



AMD auf dem Weg zum Earnings-Crossover mit Intel (Seite 2798)
eröffnet am 21.04.06 19:39:20 von
neuester Beitrag 22.04.24 09:04:17 von
neuester Beitrag 22.04.24 09:04:17 von
Beiträge: 30.442
ID: 1.055.324
ID: 1.055.324
Aufrufe heute: 91
Gesamt: 2.790.031
Gesamt: 2.790.031
Aktive User: 0
ISIN: US0079031078 · WKN: 863186 · Symbol: AMD
153,94
USD
+1,45 %
+2,20 USD
Letzter Kurs 19:42:12 Nasdaq
Neuigkeiten
Künstliche Intelligenz: Strategische Expansion: KI-Highflyer Nvidia verstärkt sich mit zwei Zukäufen 18:27 Uhr · wallstreetONLINE Redaktion |
| Advanced Micro Devices Aktien ab 5,80 Euro handeln - Ohne versteckte Kosten!Anzeige |
17:00 Uhr · BNP Paribas Anzeige |
24.04.24 · wallstreetONLINE Redaktion |
24.04.24 · BNP Paribas Anzeige |
 Künstliche Intelligenz: Strategische Expansion: KI-Highflyer Nvidia verstärkt sich mit zwei Zukäufen
Künstliche Intelligenz: Strategische Expansion: KI-Highflyer Nvidia verstärkt sich mit zwei ZukäufenWerte aus der Branche Halbleiter
| Wertpapier | Kurs | Perf. % |
|---|---|---|
| 10,870 | +43,03 | |
| 152,06 | +25,76 | |
| 5.010,00 | +25,09 | |
| 20,400 | +20,00 | |
| 1,0000 | +19,23 |
| Wertpapier | Kurs | Perf. % |
|---|---|---|
| 4,0500 | -11,96 | |
| 16,780 | -12,01 | |
| 7,5000 | -12,02 | |
| 3,3050 | -17,58 | |
| 13,590 | -22,56 |
Beitrag zu dieser Diskussion schreiben
Antwort auf Beitrag Nr.: 23.703.970 von Dresdenboy am 31.08.06 17:19:20@Dresdenboy:
Auf allen fünf Dice in Deinem untern Bild würde das Core exakt die selbe Größe einnehmen, egal ob 90nm oder 65nm.
Ich würde all das halbwegs teilen, wenn die Core-Strukturen überhaupt keine Ähnlichkeiten zwischen 90nm- und 65nm-Prozess aufweisen würden. Doch sind eindeutig weiterhin Ähnlichkeiten bei den Cores zu erkennen. Und auch der L1 müsste sich ordentlich in der Diesize reduzieren, tut es aber bei Deinen Gegenüberstellungen nicht wirklich.
UND:
Selbst wenn diese 65nm-K8 in der oberen Reihe einen 1MB-L2 hätten, dann würde dieser selbst im 65nm-Prozess noch fast 60% der Fläche des 90nm-1MB-L2 einnehmen. Doch wissen wir, dass der neue 65nm-L2 eher kleiner als 50% der Fläche des alten L2 haben soll (weil die L2 in 65nm erstmals erheblich dichtere Strukturen erhalten soll, die in der Größe denen von Intel ähneln sollten), dürfte also eher 35%-45% der Size des 90nm-L2 haben.
Würden diese 65nm-SC-K8 102mm² messen, würde 1MB-L2 rund 19mm² davon belegen. Bei Intel belegt 1MB-L2 ca. 13,7mm² in deren NGAs nach meinen Messungen. Damit läge dann AMD weiterhin noch erheblich schlechter als AMD.
Und sieht man sich die L2-Cache-Strukturen der oberen 65nm-K8 an und vergleicht sie mit den 512kB-L2-Caches von dem Quadcore unten links, dann stellen sie fast exakt die verdoppelte Strukur dieser da. UND: deren Größe ist auch fast exakt doppelt so groß => bei den L2 oben müsste es sich also um solche 1MB-L2 handeln, entsprechend meiner Annahme hier.
==> ich bin von all diesen Werten noch nicht überzeugt, es sei denn:
Sollten Deine Größenannahmen für AMDs 65nm-K8 wirklich nur annähernd stimmen, dann dürfte man wohl vermutlich von einem "broken 65nm-Prozess" bei AMD sprechen...
...mit diesen Diesizes wäre es dann bestenfalls ein 75nm-Prozess.
Lassen wir uns also überraschen, was wirklich heraus kommt...wobei ich doch hoffe, dass das wirkliche Ergebnis eher näher meinen Annahmen zu liegen kommt
Auf allen fünf Dice in Deinem untern Bild würde das Core exakt die selbe Größe einnehmen, egal ob 90nm oder 65nm.
Ich würde all das halbwegs teilen, wenn die Core-Strukturen überhaupt keine Ähnlichkeiten zwischen 90nm- und 65nm-Prozess aufweisen würden. Doch sind eindeutig weiterhin Ähnlichkeiten bei den Cores zu erkennen. Und auch der L1 müsste sich ordentlich in der Diesize reduzieren, tut es aber bei Deinen Gegenüberstellungen nicht wirklich.
UND:
Selbst wenn diese 65nm-K8 in der oberen Reihe einen 1MB-L2 hätten, dann würde dieser selbst im 65nm-Prozess noch fast 60% der Fläche des 90nm-1MB-L2 einnehmen. Doch wissen wir, dass der neue 65nm-L2 eher kleiner als 50% der Fläche des alten L2 haben soll (weil die L2 in 65nm erstmals erheblich dichtere Strukturen erhalten soll, die in der Größe denen von Intel ähneln sollten), dürfte also eher 35%-45% der Size des 90nm-L2 haben.
Würden diese 65nm-SC-K8 102mm² messen, würde 1MB-L2 rund 19mm² davon belegen. Bei Intel belegt 1MB-L2 ca. 13,7mm² in deren NGAs nach meinen Messungen. Damit läge dann AMD weiterhin noch erheblich schlechter als AMD.
Und sieht man sich die L2-Cache-Strukturen der oberen 65nm-K8 an und vergleicht sie mit den 512kB-L2-Caches von dem Quadcore unten links, dann stellen sie fast exakt die verdoppelte Strukur dieser da. UND: deren Größe ist auch fast exakt doppelt so groß => bei den L2 oben müsste es sich also um solche 1MB-L2 handeln, entsprechend meiner Annahme hier.
==> ich bin von all diesen Werten noch nicht überzeugt, es sei denn:
Sollten Deine Größenannahmen für AMDs 65nm-K8 wirklich nur annähernd stimmen, dann dürfte man wohl vermutlich von einem "broken 65nm-Prozess" bei AMD sprechen...
...mit diesen Diesizes wäre es dann bestenfalls ein 75nm-Prozess.
Lassen wir uns also überraschen, was wirklich heraus kommt...wobei ich doch hoffe, dass das wirkliche Ergebnis eher näher meinen Annahmen zu liegen kommt

Antwort auf Beitrag Nr.: 23.702.752 von Wörns am 31.08.06 16:20:14@Cache:
Mit dem HT-Protokoll habe ich mich noch nicht so befasst. Klar ist jedoch, dass eine CPU darüber in Erfahrung bringt, wer eine bestimmte Cacheline aus dem Speicher hat u. mit welchem Status. Im SMP-System wird wahrscheinlich der Speicherzugriff u. die Kohärenz-"Umfrage" zeitnah losgeschickt (es gibt da übrigens auch Patente mit Details zu diversen cHT-Geschichten).
Aber Wörns hat meiner Meinung nach Recht mit der Ungewißheit der L3-Anbindung. Da der L3 erst hinter der XBar-Anbindung der Cores auftaucht (selbst an der XBar oder gar direkt am IMC angebunden), wäre es auch kein Problem, den L3 inklusiv zu gestalten. Aus einem Core kommen nur Anfragen nach dem L2. Wie L2<->L1 gehandhabt wird, spielt für den L3 keine Rolle. Der IMC managt wahrscheinlich den L3 u. könnte dort selbst die Cachelines verwalten u. würde nur die Zugriffe der Cores beantworten. Dadurch wäre auch schon die Frage des Sharings geklärt, da ja schon der IMC selbst shared ist.
Mit dem HT-Protokoll habe ich mich noch nicht so befasst. Klar ist jedoch, dass eine CPU darüber in Erfahrung bringt, wer eine bestimmte Cacheline aus dem Speicher hat u. mit welchem Status. Im SMP-System wird wahrscheinlich der Speicherzugriff u. die Kohärenz-"Umfrage" zeitnah losgeschickt (es gibt da übrigens auch Patente mit Details zu diversen cHT-Geschichten).
Aber Wörns hat meiner Meinung nach Recht mit der Ungewißheit der L3-Anbindung. Da der L3 erst hinter der XBar-Anbindung der Cores auftaucht (selbst an der XBar oder gar direkt am IMC angebunden), wäre es auch kein Problem, den L3 inklusiv zu gestalten. Aus einem Core kommen nur Anfragen nach dem L2. Wie L2<->L1 gehandhabt wird, spielt für den L3 keine Rolle. Der IMC managt wahrscheinlich den L3 u. könnte dort selbst die Cachelines verwalten u. würde nur die Zugriffe der Cores beantworten. Dadurch wäre auch schon die Frage des Sharings geklärt, da ja schon der IMC selbst shared ist.
Antwort auf Beitrag Nr.: 23.701.062 von BavarianRealist am 31.08.06 15:03:59Dem frühen Vergleich von Hans brachte ich erstmal Skepsis entgegen, als sich herausstellte, dass das 65nm Production Sample ja etwa im Bereich von 100mm² liegt (natürlich mit noch viel Platz auf dem Die). Hier eine verkleinerte Version des Vergleichs, wo ich schon schrieb, dass das 65nm-Die sogar ein klein wenig größer sein müsste, um mit dem Wafer übereinzustimmen:

Nun schau man sich die Cores an -> da tut sich in der Gesamtfläche fast nix hin zu 65nm (ich habe ja schon die 80/89%-Faktoren genannt). Hans ging ja für seine Schätzung einfach von einem Shrink der Fläche auf die Hälfte des auf dem Bild entspr. skalierten K8L.
Ich habe nun alles noch einmal grafisch aufgearbeitet u. auf einen Maßstab gebracht (basierend auf 300mm-Wafer mit den 65nm-Prototypen, Rev. F-Größenangabe u. 65nm-L2-Cachegrößen):

Nun schau man sich die Cores an -> da tut sich in der Gesamtfläche fast nix hin zu 65nm (ich habe ja schon die 80/89%-Faktoren genannt). Hans ging ja für seine Schätzung einfach von einem Shrink der Fläche auf die Hälfte des auf dem Bild entspr. skalierten K8L.
Ich habe nun alles noch einmal grafisch aufgearbeitet u. auf einen Maßstab gebracht (basierend auf 300mm-Wafer mit den 65nm-Prototypen, Rev. F-Größenangabe u. 65nm-L2-Cachegrößen):
@Sven.K
Das hast du schon richtig verstanden. Bei AMD ist L1- und L2-Cache exklusiv, d.h. nicht redundant sondern was aus dem L1-Cache rausfällt, kommt in den L2-Cache hinein. Damit steht aber noch nicht fest, wie der L3-Cache angebunden ist.
Appropos, ich habe das Cache-Protokoll (MOESI) nie ganz verstanden. Versteht jemand (vielleicht Drebo?), wie bei einem Speicherzugriff in einem Opteron 8xx System der anfragende Prozessor Nr.3 rauskriegt, dass die betroffene Speicherzelle sich nicht im Arbeitsspeicher sondern im Cache von Prozessor Nr.2 befindet? Geschieht das am Ende nur über die Timings, d.h. ein per HT angebundener Cache eines anderen Prozessors sagt immer schneller "hier!" als der Arbeitsspeicher? MfG
Das hast du schon richtig verstanden. Bei AMD ist L1- und L2-Cache exklusiv, d.h. nicht redundant sondern was aus dem L1-Cache rausfällt, kommt in den L2-Cache hinein. Damit steht aber noch nicht fest, wie der L3-Cache angebunden ist.
Appropos, ich habe das Cache-Protokoll (MOESI) nie ganz verstanden. Versteht jemand (vielleicht Drebo?), wie bei einem Speicherzugriff in einem Opteron 8xx System der anfragende Prozessor Nr.3 rauskriegt, dass die betroffene Speicherzelle sich nicht im Arbeitsspeicher sondern im Cache von Prozessor Nr.2 befindet? Geschieht das am Ende nur über die Timings, d.h. ein per HT angebundener Cache eines anderen Prozessors sagt immer schneller "hier!" als der Arbeitsspeicher? MfG
Antwort auf Beitrag Nr.: 23.701.015 von BavarianRealist am 31.08.06 15:01:42@BR
AMDs Cache ist doch Exclusive und nicht inclusive wie bei Intel
(IMHO). Also Sachen im L2 sind nicht im L3 und vice-versa. Siehe
auch L1/L2. Bei Intel enthält der L3 doch Daten der L2 oder
missverstehe ich da was?
SvenK
AMDs Cache ist doch Exclusive und nicht inclusive wie bei Intel
(IMHO). Also Sachen im L2 sind nicht im L3 und vice-versa. Siehe
auch L1/L2. Bei Intel enthält der L3 doch Daten der L2 oder
missverstehe ich da was?
SvenK
Trading Spotlight
Antwort auf Beitrag Nr.: 23.700.723 von Dresdenboy am 31.08.06 14:42:24@Dresdenboy: "...Für das Bild mit dem neuen Core:
3041:35, ergibt 87. Das spricht für einen 300mm-Wafer..."
Danke für das Nachmessen!
Dann sind womöglich auf dem Wafer doch 90nm-"vor"-K8L-Dice, so wie ich auch schon gestern spekuliert hatte. Könnte AMD gar planen, noch ein paar dieser 90nm-"vor"-K8L auszuliefern???

3041:35, ergibt 87. Das spricht für einen 300mm-Wafer..."
Danke für das Nachmessen!
Dann sind womöglich auf dem Wafer doch 90nm-"vor"-K8L-Dice, so wie ich auch schon gestern spekuliert hatte. Könnte AMD gar planen, noch ein paar dieser 90nm-"vor"-K8L auszuliefern???

Antwort auf Beitrag Nr.: 23.700.723 von Dresdenboy am 31.08.06 14:42:24@Dresdenboy:
Sorry, wenn ich Dir hier klar widersprechen muss: rund 320mm² dürfte die Diesize für ein Quadcore in 90nm sein.
Und das ginge ganz einfach daraus hervor:
Sieht man sich das Bild unten an, so haben hierin die Cores vom Dualcore die gleiche "optische" Größe wie die des Quadcores, wie der gelbe Rahmen schön zeigt.
==> demnach müsste ein in 90nm gefertigter Quadcore eben im Verhältnis zum Dualcore entsprechend größer sein, so wie es unten stehendes Bild widergibt. Und auf dem Bild würde der so skizzierte Quadcore rund 1,45mal größer sein, also 1,45*220mm²=318mm² messen.
==> in 65nm müsste er dann entsprechend kleiner sein. Mit einem Shrink-Faktor von ca. 0,6 ergäbe sich dann für den skizzierten Quadcore 318mm²*0,6=190mm². Eine Größe von um die 200mm² für den Quadcore-K8L halte ich auf für realistisch: AMD wird den L3 so große machen, dass man wohl in diesen Bereich kommen wird.
Ach ja:
Macht eigentlich ein 2MB-L3 überhaupt Sinn, wenn alleine die vier 512kB-L2 ebenfalls 2MB hätten? Wenn der L3 nicht mehr Speicher zur Verfügung stellt als der gesamte L2, dann wäre er doch nur hinderlich, oder? Demnach würde dieses Konzept doch nur Sinn machen, wenn der L3 erheblich größer wäre, also ab 8MB, oder? Vielleicht doch schon Z-Ram?
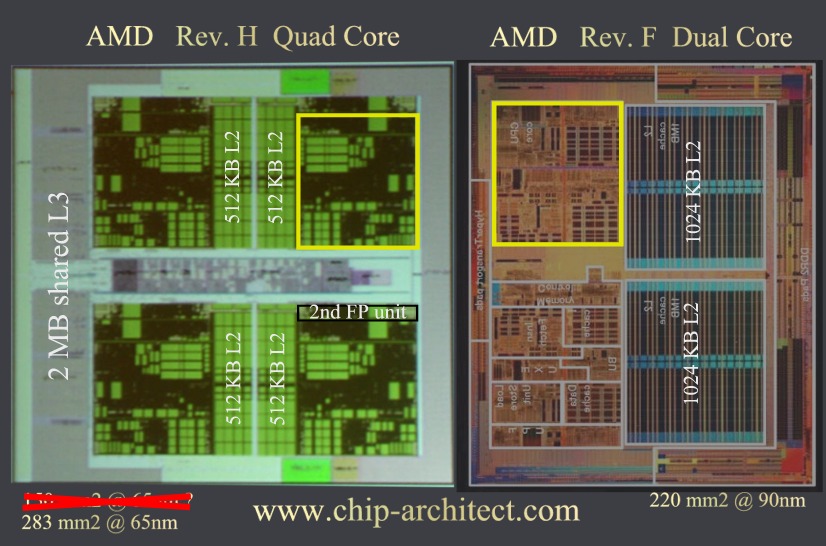
Sorry, wenn ich Dir hier klar widersprechen muss: rund 320mm² dürfte die Diesize für ein Quadcore in 90nm sein.
Und das ginge ganz einfach daraus hervor:
Sieht man sich das Bild unten an, so haben hierin die Cores vom Dualcore die gleiche "optische" Größe wie die des Quadcores, wie der gelbe Rahmen schön zeigt.
==> demnach müsste ein in 90nm gefertigter Quadcore eben im Verhältnis zum Dualcore entsprechend größer sein, so wie es unten stehendes Bild widergibt. Und auf dem Bild würde der so skizzierte Quadcore rund 1,45mal größer sein, also 1,45*220mm²=318mm² messen.
==> in 65nm müsste er dann entsprechend kleiner sein. Mit einem Shrink-Faktor von ca. 0,6 ergäbe sich dann für den skizzierten Quadcore 318mm²*0,6=190mm². Eine Größe von um die 200mm² für den Quadcore-K8L halte ich auf für realistisch: AMD wird den L3 so große machen, dass man wohl in diesen Bereich kommen wird.
Ach ja:
Macht eigentlich ein 2MB-L3 überhaupt Sinn, wenn alleine die vier 512kB-L2 ebenfalls 2MB hätten? Wenn der L3 nicht mehr Speicher zur Verfügung stellt als der gesamte L2, dann wäre er doch nur hinderlich, oder? Demnach würde dieses Konzept doch nur Sinn machen, wenn der L3 erheblich größer wäre, also ab 8MB, oder? Vielleicht doch schon Z-Ram?
Antwort auf Beitrag Nr.: 23.700.476 von BavarianRealist am 31.08.06 14:27:43Nachtrag:
rkinet kam mir auch schon mit dem Core2
Das die L2-Zellen überproportional schrumpfen (aber die Logik zwischen den Arrays spielt auch eine Rolle), hab ich dir ja im langen Beitrag vorgerechnet. Die Logik im Core schrumpft ja demnach auch nach Plan.
Machen wir eine Rückrechnung zur Verifikation (hättest du ja mal machen können ):
):
Da der Wafer von Image_0084f offensichtlich 300mm Durchmesser hat, können wir den L2 ja in mm² berechnen:
30x58 ergäbe bei den 10px/mm (Wafer hat 3030px Durchmesser, also max. 1% Fehler, bzw. ca. 2% bei Flächen) dann 17,4 mm²
Der K8L-Die auf dem Dieplot von ist auf dem de Vriesschen Bild immer noch 543x516 groß, bzw. 280188 Pixel. Für 299 mm² ergibt das 937 Pixel/mm². 512 kB L2 sind 46x177 Pixel groß, also 8142 Pixel.
Bei den 937 Pixel/mm² ergibt das 8,7 mm² bzw. 17,4 mm² für 1 MB.
So, und nu?

rkinet kam mir auch schon mit dem Core2
Das die L2-Zellen überproportional schrumpfen (aber die Logik zwischen den Arrays spielt auch eine Rolle), hab ich dir ja im langen Beitrag vorgerechnet. Die Logik im Core schrumpft ja demnach auch nach Plan.
Machen wir eine Rückrechnung zur Verifikation (hättest du ja mal machen können
 ):
):Da der Wafer von Image_0084f offensichtlich 300mm Durchmesser hat, können wir den L2 ja in mm² berechnen:
30x58 ergäbe bei den 10px/mm (Wafer hat 3030px Durchmesser, also max. 1% Fehler, bzw. ca. 2% bei Flächen) dann 17,4 mm²
Der K8L-Die auf dem Dieplot von ist auf dem de Vriesschen Bild immer noch 543x516 groß, bzw. 280188 Pixel. Für 299 mm² ergibt das 937 Pixel/mm². 512 kB L2 sind 46x177 Pixel groß, also 8142 Pixel.
Bei den 937 Pixel/mm² ergibt das 8,7 mm² bzw. 17,4 mm² für 1 MB.
So, und nu?

Antwort auf Beitrag Nr.: 23.700.010 von BavarianRealist am 31.08.06 14:02:44Widerlegung der 200mm-Wafer-Theorie:
Nehmen wir http://amd-images.de/PICS/process/zips/Image_0102f.zip hinzu u. vergleichen das Verhältnis der Kerbe im oberen Rand zum Durchmesser.
Für das 2-Wafer-Bild:
200mm-Wafer: 1343:24, ergibt 56
300mm-Wafer: 2020:23, ergibt 88 (bei Kerbenbreite 24 dann 84)
Für das Bild mit dem neuen Core:
3041:35, ergibt 87. Das spricht für einen 300mm-Wafer.
q.e.d.
Die Cores auf diesem Wafer (aufgrund der errechneten Strukturgrößenänderungen äußerst wahrscheinlich schon in 65nm) passen sehr gut auf die des K8L-QC-Die bis auf die IMCs u. 2.FPU-Teil. Die L2-Caches ebenso. Wenn diese Größen beim K8L bleiben, bleibt auch die errechnete Gesamtgröße.
Ich tendiere eher zu dem ~300mm²-Ergebnis. Selbst rkinet akzeptiert das
Da die Cores bei einer Fläche von 71% der 90nm-Cores (basierend auf der 65nm-90nm-Gegenüberstellung, wahrscheinlich sogar mehr als 71%) u. der erweiterten FPU, großer I/O-Fläche, anteilsmäßig großer Crossbar u. zusätzlichem L3-Cache von der Fläche her sehr umfangreich sind, wäre das gar nicht so abwegig und aufgrund der hohen Redundanz auch tragbar.
Für Investitionsentscheidungen (worum es hier ja indirekt geht) ist es schon wichtig, vorhandene/veröffentlichte Fakten möglichst nah an der Wahrheit oder eher vorsichtig als überschwänglich zu interpretieren.
Nehmen wir http://amd-images.de/PICS/process/zips/Image_0102f.zip hinzu u. vergleichen das Verhältnis der Kerbe im oberen Rand zum Durchmesser.
Für das 2-Wafer-Bild:
200mm-Wafer: 1343:24, ergibt 56
300mm-Wafer: 2020:23, ergibt 88 (bei Kerbenbreite 24 dann 84)
Für das Bild mit dem neuen Core:
3041:35, ergibt 87. Das spricht für einen 300mm-Wafer.
q.e.d.
Die Cores auf diesem Wafer (aufgrund der errechneten Strukturgrößenänderungen äußerst wahrscheinlich schon in 65nm) passen sehr gut auf die des K8L-QC-Die bis auf die IMCs u. 2.FPU-Teil. Die L2-Caches ebenso. Wenn diese Größen beim K8L bleiben, bleibt auch die errechnete Gesamtgröße.
Ich tendiere eher zu dem ~300mm²-Ergebnis. Selbst rkinet akzeptiert das
Da die Cores bei einer Fläche von 71% der 90nm-Cores (basierend auf der 65nm-90nm-Gegenüberstellung, wahrscheinlich sogar mehr als 71%) u. der erweiterten FPU, großer I/O-Fläche, anteilsmäßig großer Crossbar u. zusätzlichem L3-Cache von der Fläche her sehr umfangreich sind, wäre das gar nicht so abwegig und aufgrund der hohen Redundanz auch tragbar.
Für Investitionsentscheidungen (worum es hier ja indirekt geht) ist es schon wichtig, vorhandene/veröffentlichte Fakten möglichst nah an der Wahrheit oder eher vorsichtig als überschwänglich zu interpretieren.
@Dresdenboy:
Man bedenke:
Intels 4MB-L2-NGA hat eine Diesize von 145mm² bei 65nm!
AMDs Rev.E-DC-CPU mit 2x512kB hat ebenfalls nur eine Diesize von 145mm² aber noch bei 90nm!
Auch diese "Gleichung" führt mich zum der Annahme, dass AMDs 65nm-Quadcore kaum größer als 150mm² werden dürfte, insbesondere weil ja diesemal die L2-Cellen überproportional schrumpfen sollen.
Man bedenke:
Intels 4MB-L2-NGA hat eine Diesize von 145mm² bei 65nm!
AMDs Rev.E-DC-CPU mit 2x512kB hat ebenfalls nur eine Diesize von 145mm² aber noch bei 90nm!
Auch diese "Gleichung" führt mich zum der Annahme, dass AMDs 65nm-Quadcore kaum größer als 150mm² werden dürfte, insbesondere weil ja diesemal die L2-Cellen überproportional schrumpfen sollen.




















Künstliche Intelligenz: Strategische Expansion: KI-Highflyer Nvidia verstärkt sich mit zwei Zukäufen 18:27 Uhr · wallstreetONLINE Redaktion · Advanced Micro Devices |
17:00 Uhr · BNP Paribas · Advanced Micro DevicesAnzeige |
24.04.24 · wallstreetONLINE Redaktion · Advanced Micro Devices |
24.04.24 · dpa-AFX · Advanced Micro Devices |
24.04.24 · wallstreetONLINE Redaktion · Advanced Micro Devices |
22.04.24 · wallstreetONLINE Redaktion · Advanced Micro Devices |
22.04.24 · wallstreetONLINE Redaktion · Advanced Micro Devices |
21.04.24 · Dr. Hamed Esnaashari · Adobe |