



Ein Schwindel, der verjährt: unterschlagene Daten
eröffnet am 21.10.23 17:55:24 von
neuester Beitrag 18.01.24 19:28:40 von
neuester Beitrag 18.01.24 19:28:40 von
Beiträge: 12
ID: 1.373.086
ID: 1.373.086
Aufrufe heute: 2
Gesamt: 1.580
Gesamt: 1.580
Aktive User: 0
Top-Diskussionen
| Titel | letzter Beitrag | Aufrufe |
|---|---|---|
| heute 15:47 | 3084 | |
| heute 16:23 | 3068 | |
| vor 8 Minuten | 1657 | |
| vor 6 Minuten | 1404 | |
| vor 16 Minuten | 1285 | |
| vor 1 Stunde | 1222 | |
| vor 54 Minuten | 1182 | |
| heute 15:09 | 1172 |
Meistdiskutierte Wertpapiere
| Platz | vorher | Wertpapier | Kurs | Perf. % | Anzahl | ||
|---|---|---|---|---|---|---|---|
| 1. | 1. | 18.001,60 | +0,59 | 240 | |||
| 2. | 2. | 168,20 | +0,08 | 87 | |||
| 3. | 3. | 9,7000 | +12,27 | 75 | |||
| 4. | 14. | 6,1400 | -1,35 | 69 | |||
| 5. | 11. | 0,1865 | 0,00 | 52 | |||
| 6. | 7. | 0,8750 | -12,50 | 47 | |||
| 7. | 12. | 0,1561 | +2,97 | 38 | |||
| 8. | 6. | 2.302,50 | 0,00 | 36 |
Beitrag zu dieser Diskussion schreiben
Antwort auf Beitrag Nr.: 75.103.422 von naturfan2 am 15.01.24 11:19:06Zunächst einmal danke für das Lob.
Ich wollte diesen Thread nicht so aufbauen, dass ich mich pausenlos mit mir selbst unterhalte, sondern wenige, relevante Beiträge bereit stellen, die wirklich das Thema betreffen und auch nach längerer Zeit noch von Interesse sind. In diesem Sinne melde ich mich hier nicht zu oft.
Das heutige Thema ist eine besondere Form des Rosinenpickens. Ich unterscheide einseitiges und zweiseitiges Ronsinenpicken. Das einseitige Rosinenpicken ist, dass man sich die Daten anschaut, die bis zum aktuellen Zeitpunkt vorliegt, und den Anfangspunkt der Betrachtung so herauspickt, dass etwas anderes herauskommt, als bei Betrachtung eines größeren Datensatzes. Das zweiseitige Rosinenpicken bedeutet, dass man auch willkürlich einen Endpunkt der betrachteten Daten vorgibt. Dieses Verhalten macht natürlich noch deutlicher, dass das Rosinenpicken vorsätzlich geschieht, um die Interpretation der Daten zu verfälschen. In jedem Fall unterschlägt man Daten, die objektiv vorhanden sind. In dem einen Fall könnte man aber immerhin annehmen, dass jemand ehrlich fragen sollte, wie denn die aktuelle Entwicklung ist und dabei dieses Anfangspunktproblem nicht verstanden hat. Für die zusätzliche Einschränkung auf ältere Daten unterschlägt man aber sehr aktiv das zusätzliche Wissen, das die neuen Daten bieten, und da ist keine Ausrede denkbar.
Mein Beispiel hier sind die Satellitendaten. Es gibt einen bestmmten Satz von Satelliten, die die Mikrowellenstrahlung der Erde beobachten. Und jedes Mal, wenn ein Satellit aus dem Verkehr genommen und ein neuer Satellit hochgeschickt wird, steht man vor dem Problem, die Daten der verschiedenen Satelliten miteinander stimmig zu machen. Die Instrumente haben einen erheblichen Kalibrierungsunterschied. Im Grunde könnte es also nur einen Satellitenzeitreihe geben, aber tatsächlich gibt es mehrere, insbesondere RSS und UAH. Eine Zeit lang wurde ausgerechnet RSS von Leugnern geliebt. Der Grund dafür ist die relativ starke Sensitivität der Satellitendaten für El Nino-Ereignisse. Die Satellitendaten betonen diese Ereignisse viel stärker. Das liegt auch daran, dass die Sateliten keine Daten südlich des 70. Breitengrades und nördlich von 82,5 Grad nödlicher Breite berücksichtigen. Die Tropen sind überbetont und daher wirkt sich El Nino hier stärker aus. Als die Bodendaten bereits zeigten, dass ja wohl doch auch ab 1998 ein Temperaturanstieg nachweisbar ist, kontne man bei den RSS-Daten noch von einer angeblichen "Pause" reden.
Das folgende Diagramm zeigt die RSS-Daten, wie sie von RSS selbst gepostet werden:
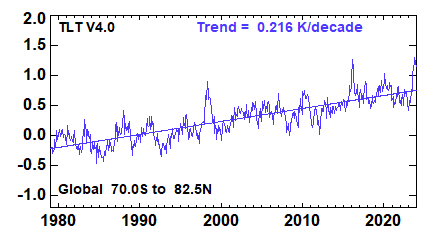
Das ist sehr klar ein stark positiver Trend, stärker als bei den Bodendaten.
Und diese Bildchen sind in Leugnerblogs verbreitet worden, vor allem bei Wattsupwiththat, und gerne weiter verbreitet worden:
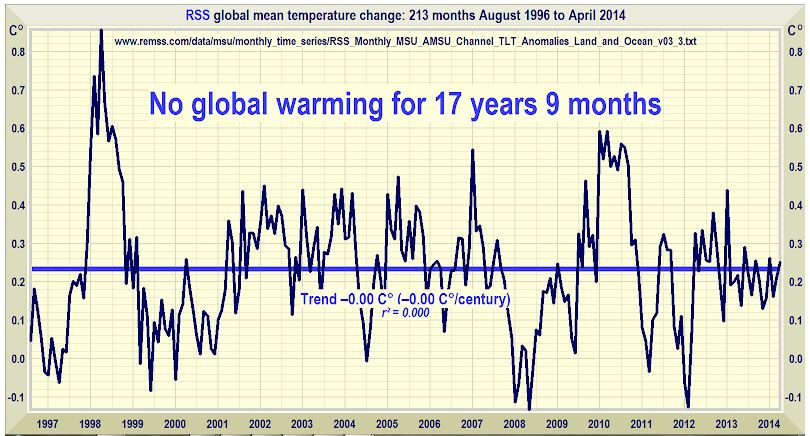
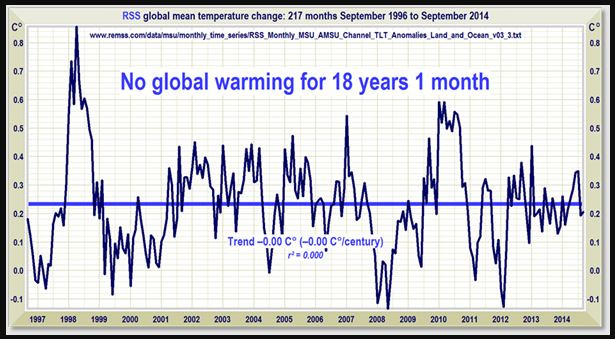
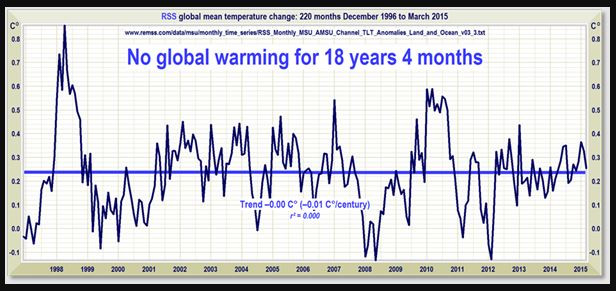
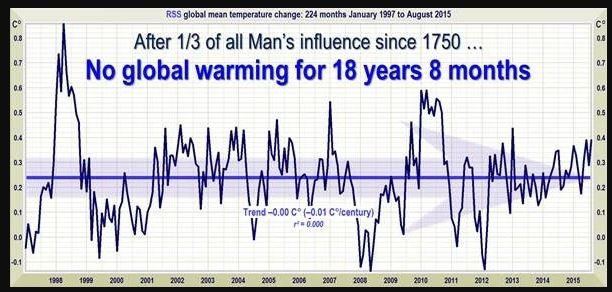
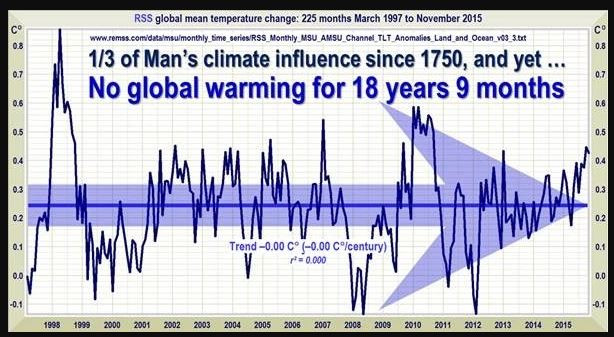
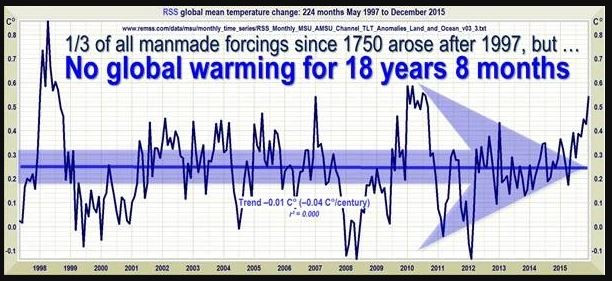
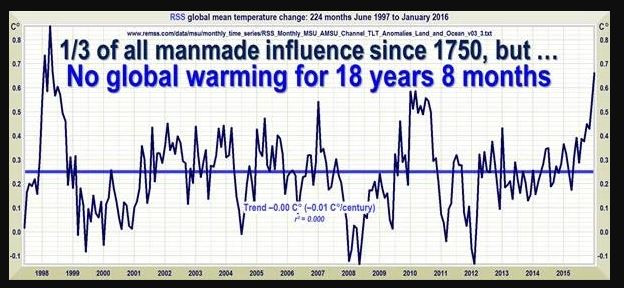
Man sieht, dass da über einen längeren Zeitraum die Erzählung von der angeblich nicht stattfindenden globalen Erwärmung mit den RSS-Daten verbreitet wurde. Damals waren diese Daten anscheinend für Leugner das Gelbe vom Ei, der beste Datensatz. Aber bei genauerem Hinschauen fällt auf, dass sich der Anfangspunkt dieser angeblichen Pause verschiebt. Im obersten Bild fängt das noch August 1996 an, dann September 1996, Dezember 1996, Januar 1997, März 1997, Mai 1997 und zuletzt Juni 1997. Der Anfangspunkt des Rosinenpickens wandert also fast ein Jahr. Das heißt aber, indirekt gibt man zu, dass im ersten Bildchen das erste Jahr angeblicher Pause gar keine Pause enthielt. Der Endpunkt ist natürlich mit der Veröffentlichung jeden neuen Monats an Daten weiter gewandert. Und dann war Ende Gelände - keine Pause mehr, weil nun die neuen Daten, egal wie stark man den Anfangspunkt noch verschob, keine angebliche "Pause" zuließen. An dem Punkt hätte ein ehrlicher Skeptiker sagen müssen: in Wahrheit gibt es keine "Pause". Vielmehr zeigen die neuen Daten, dass da immer ein ansteigender Trend ist.
Leugner sind nun keine Skeptiker. Für sie ging es nun um das "Rechthaben". Das heißt, es sollte nicht mehr über das geredet werden, was relevant ist, nämlich ob man denn da jetzt einen Trend sieht. Sondern nur noch darüber, dass da eben ein Ausschnitt aus den Daten erstellt werden kann, in dem man den Trend nicht sieht. Man könnte da schon fragen: lieber Leugner, du schneidest retrospektiv da Daten heraus und ich sehe hier 7 Varianten. Warum soll eine bestimmte davon richtig sein und welche denn davon? Man könnte auch fragen: sowohl vor diesem Ausschnitt, als auch danach habe ich aber weitere Daten. Warum darf ich die nicht berücksichtigen? Die Diskussion üebr eine angebliche "Pause" hatte mal einen konkreten Sinn: man wollte damit behaupten, dass die globale Erwärmung durch den Treibhauseffekt nur eine Erfindung wäre. Diese Erwärmung müsste ja immer weiter gehen. Wenn man aber zeigen kann, dass es sich gar nicht mehr weiter erwärmt, dann muss ja auch die Erwärmung davor eine andere Ursache gehabt haben - nicht Treibhauseffekt, sondern Sonne oder PDO oder so. Das Bild ganz oben von der RSS-Seite zeigt also, dass der Trend weiter geht und das natürlich das ist, was wir aufgrund des Treibhauseffektes erwarten. Aber wenn es nur noch um "Rechthaberei" geht, spielt es keine Rolle mehr. Man streitet nur darum, dass da aber mal eine Pause war. Also aufgrund zweiseitigen Rosinenpickens.
Nun kann man in verschiedener Weise dieses zweiseitige Rosinenpicken entlarven. Am einfachsten, indem man so ein Schwindeldiagramm im Kontext aller Daten zeigt:
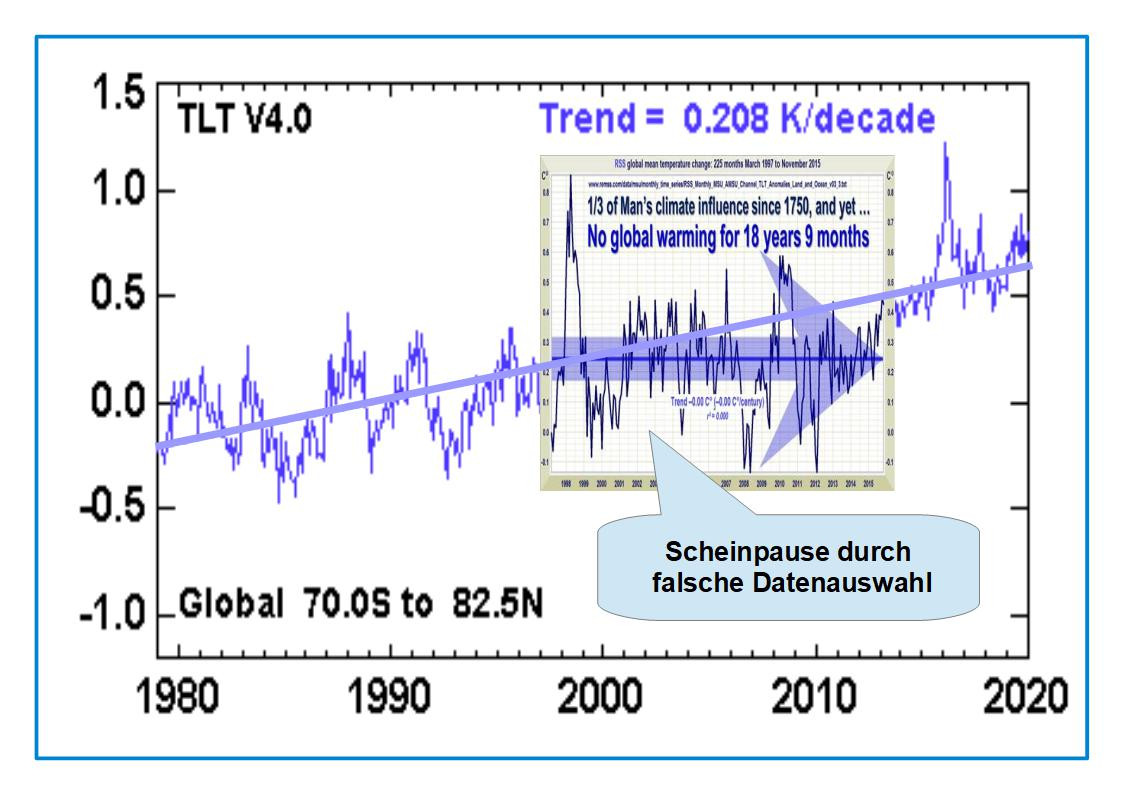
Man sieht gleich: das ist vom Dezember 2019. Es ist langweilig, so ein Bild mit weiteren Daten neu zu erstellen, weil das Prinzip ja schon klar ist.
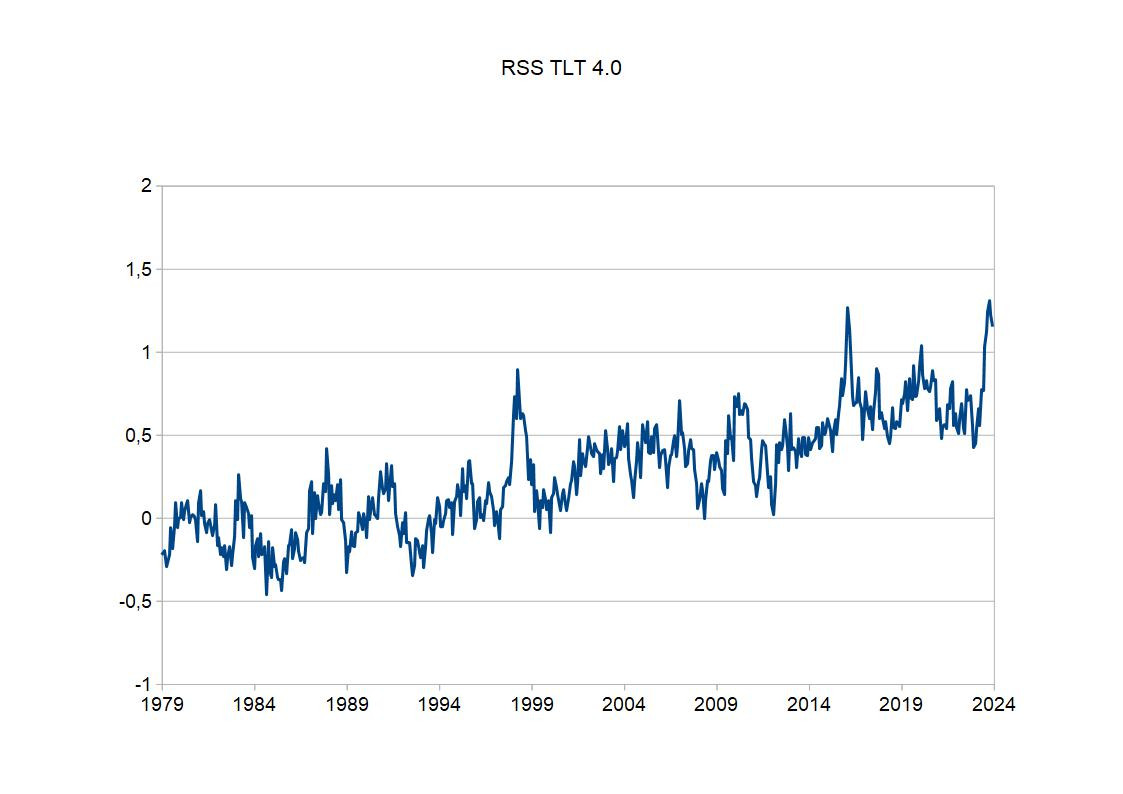
Ich kann aber natürlich auch die RSS-Daten herunterladen und selbst im Diagramm darstellen. Man kann also das Bild mit dem ganz oben vergleichen - bei mir ist jetzt nur die Linie dicker:
Ich kann auch eines der "Pausenbilder" von oben neu erstellen:
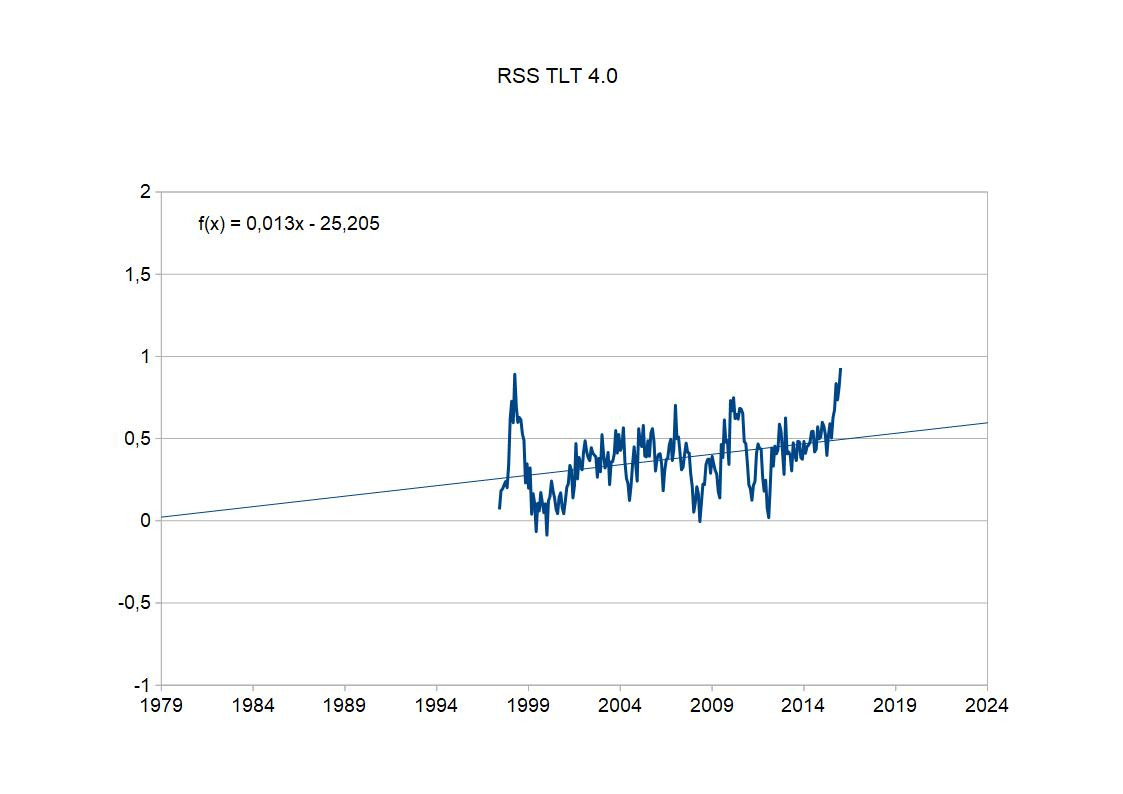
Ich habe auch gleich den Trend eingezeichnet - 0,13 Grad/Jahrzehnt. Aber Moment mal - wieso ein Trend? Na, die schönen Pausenbilder sind alle noch die RSS TLT 3.3-Version. Doch inzwischen sind die Verfahren verbessert worden, und wir sind bei RSS TLT Version 4.0. Wir erinnern uns: die Kalibrierungsunterschiede zwischen den Mikrowellensensoren der verschiedenen Satelliten. Hier und in anderen Details hat man Verbesserungen durchgeführt. Es hat sich nicht viel geändert - man kann mein aktuelles Bild mit dem alten "Pausenbild" vergleichen - da sind alle Zacken drin, sie sind nur minimal verschoben. Aber angesichts dieses kurzen herausgepickten Zeitraums wirkt sich das erheblich auf den Trend aus. Also ganz klar, die aktuellen Daten zeigen einfach keine Pause mehr. Die Bildchen von oben mit den angeblichen "Pausen" sind nicht nur zweiseitig rosinengepickt, sondern dazu noch veraltet. Und damit falsch.
Aber es geht noch besser: alle Bildchen zusammen behaupten, da wäre seit August 1996 eine Pause gewesen und Januar 2016 hat man das zum letzten Mal behauptet. Schauen wir uns doch mal den kompletten Zeitraum an, in dem angeblich für jeden Monat behaupten kann, dass der zu einer "Pause" gehört.
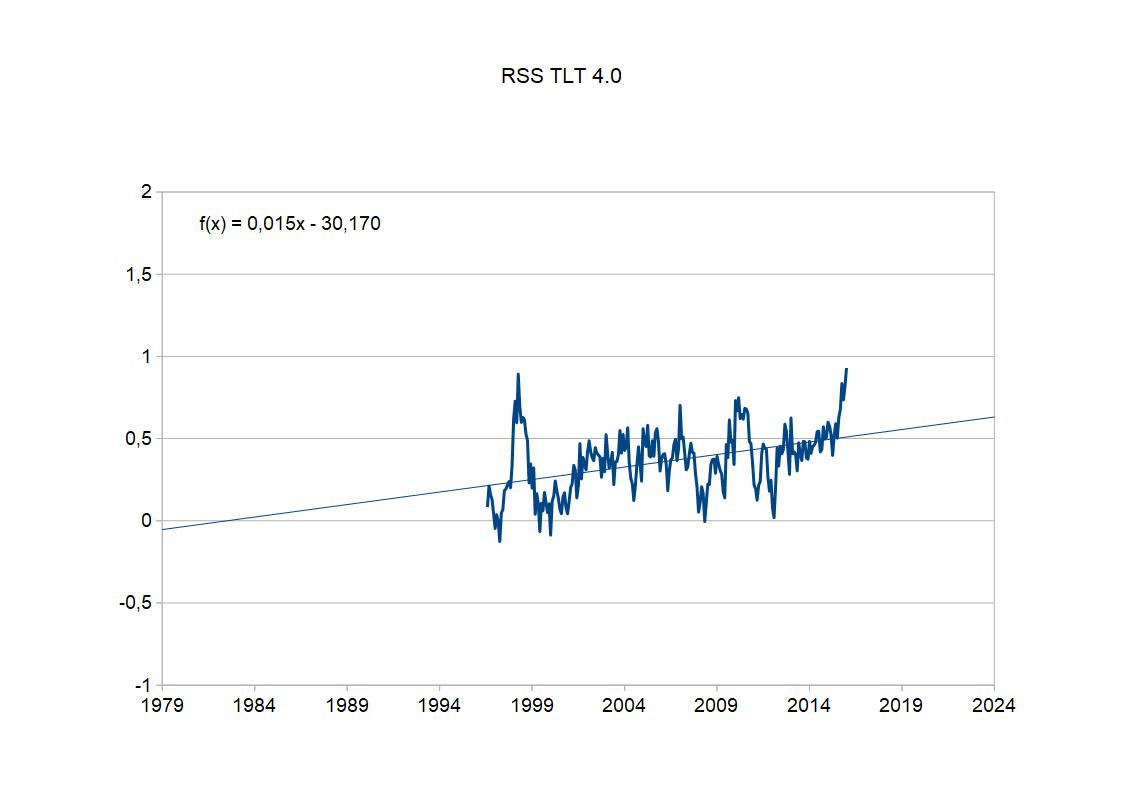
Da kommen noch 10 Monate dazu - von August 1996 bis Januar 2016 war dieses Pausentheater. Und der Trend steigt gleich noch einmal auf 0,15 Grad/Jahrzehnt. Die angeblichen Pausen waren nicht rosinengepickt, und zwar zweiseitig, sondern auch noch durch inzwischen veraltete Daten verursacht. Mit den aktuellen Daten findet man da keine "Pausen" mehr.
Und jetzt zum Schluß die angebliche Pause eingebettet in alle Daten:
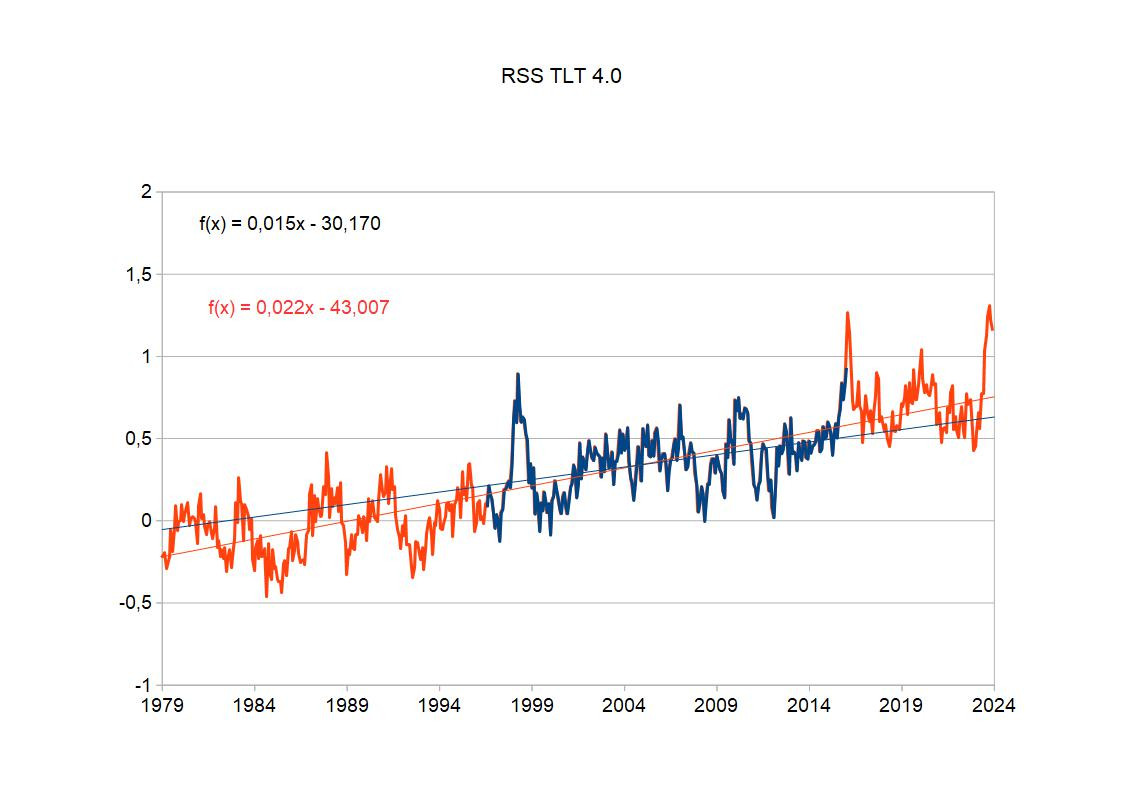
Offensichtlich unterscheidet sich der Trend der angeblichen "Pause" nicht wirklich von dem aller Daten. Man sieht nur den Effekt eines Herauspickens, mit dem man die Unsicherheit vergrößert.
Sicherlich ein Augenöffner, mal mit allen Bildern im Zusammenhang zu sehen, mit welchen angeblichen "Pausen" Leugner inzwischen argumentieren.
Ich wollte diesen Thread nicht so aufbauen, dass ich mich pausenlos mit mir selbst unterhalte, sondern wenige, relevante Beiträge bereit stellen, die wirklich das Thema betreffen und auch nach längerer Zeit noch von Interesse sind. In diesem Sinne melde ich mich hier nicht zu oft.
Das heutige Thema ist eine besondere Form des Rosinenpickens. Ich unterscheide einseitiges und zweiseitiges Ronsinenpicken. Das einseitige Rosinenpicken ist, dass man sich die Daten anschaut, die bis zum aktuellen Zeitpunkt vorliegt, und den Anfangspunkt der Betrachtung so herauspickt, dass etwas anderes herauskommt, als bei Betrachtung eines größeren Datensatzes. Das zweiseitige Rosinenpicken bedeutet, dass man auch willkürlich einen Endpunkt der betrachteten Daten vorgibt. Dieses Verhalten macht natürlich noch deutlicher, dass das Rosinenpicken vorsätzlich geschieht, um die Interpretation der Daten zu verfälschen. In jedem Fall unterschlägt man Daten, die objektiv vorhanden sind. In dem einen Fall könnte man aber immerhin annehmen, dass jemand ehrlich fragen sollte, wie denn die aktuelle Entwicklung ist und dabei dieses Anfangspunktproblem nicht verstanden hat. Für die zusätzliche Einschränkung auf ältere Daten unterschlägt man aber sehr aktiv das zusätzliche Wissen, das die neuen Daten bieten, und da ist keine Ausrede denkbar.
Mein Beispiel hier sind die Satellitendaten. Es gibt einen bestmmten Satz von Satelliten, die die Mikrowellenstrahlung der Erde beobachten. Und jedes Mal, wenn ein Satellit aus dem Verkehr genommen und ein neuer Satellit hochgeschickt wird, steht man vor dem Problem, die Daten der verschiedenen Satelliten miteinander stimmig zu machen. Die Instrumente haben einen erheblichen Kalibrierungsunterschied. Im Grunde könnte es also nur einen Satellitenzeitreihe geben, aber tatsächlich gibt es mehrere, insbesondere RSS und UAH. Eine Zeit lang wurde ausgerechnet RSS von Leugnern geliebt. Der Grund dafür ist die relativ starke Sensitivität der Satellitendaten für El Nino-Ereignisse. Die Satellitendaten betonen diese Ereignisse viel stärker. Das liegt auch daran, dass die Sateliten keine Daten südlich des 70. Breitengrades und nördlich von 82,5 Grad nödlicher Breite berücksichtigen. Die Tropen sind überbetont und daher wirkt sich El Nino hier stärker aus. Als die Bodendaten bereits zeigten, dass ja wohl doch auch ab 1998 ein Temperaturanstieg nachweisbar ist, kontne man bei den RSS-Daten noch von einer angeblichen "Pause" reden.
Das folgende Diagramm zeigt die RSS-Daten, wie sie von RSS selbst gepostet werden:

Das ist sehr klar ein stark positiver Trend, stärker als bei den Bodendaten.
Und diese Bildchen sind in Leugnerblogs verbreitet worden, vor allem bei Wattsupwiththat, und gerne weiter verbreitet worden:







Man sieht, dass da über einen längeren Zeitraum die Erzählung von der angeblich nicht stattfindenden globalen Erwärmung mit den RSS-Daten verbreitet wurde. Damals waren diese Daten anscheinend für Leugner das Gelbe vom Ei, der beste Datensatz. Aber bei genauerem Hinschauen fällt auf, dass sich der Anfangspunkt dieser angeblichen Pause verschiebt. Im obersten Bild fängt das noch August 1996 an, dann September 1996, Dezember 1996, Januar 1997, März 1997, Mai 1997 und zuletzt Juni 1997. Der Anfangspunkt des Rosinenpickens wandert also fast ein Jahr. Das heißt aber, indirekt gibt man zu, dass im ersten Bildchen das erste Jahr angeblicher Pause gar keine Pause enthielt. Der Endpunkt ist natürlich mit der Veröffentlichung jeden neuen Monats an Daten weiter gewandert. Und dann war Ende Gelände - keine Pause mehr, weil nun die neuen Daten, egal wie stark man den Anfangspunkt noch verschob, keine angebliche "Pause" zuließen. An dem Punkt hätte ein ehrlicher Skeptiker sagen müssen: in Wahrheit gibt es keine "Pause". Vielmehr zeigen die neuen Daten, dass da immer ein ansteigender Trend ist.
Leugner sind nun keine Skeptiker. Für sie ging es nun um das "Rechthaben". Das heißt, es sollte nicht mehr über das geredet werden, was relevant ist, nämlich ob man denn da jetzt einen Trend sieht. Sondern nur noch darüber, dass da eben ein Ausschnitt aus den Daten erstellt werden kann, in dem man den Trend nicht sieht. Man könnte da schon fragen: lieber Leugner, du schneidest retrospektiv da Daten heraus und ich sehe hier 7 Varianten. Warum soll eine bestimmte davon richtig sein und welche denn davon? Man könnte auch fragen: sowohl vor diesem Ausschnitt, als auch danach habe ich aber weitere Daten. Warum darf ich die nicht berücksichtigen? Die Diskussion üebr eine angebliche "Pause" hatte mal einen konkreten Sinn: man wollte damit behaupten, dass die globale Erwärmung durch den Treibhauseffekt nur eine Erfindung wäre. Diese Erwärmung müsste ja immer weiter gehen. Wenn man aber zeigen kann, dass es sich gar nicht mehr weiter erwärmt, dann muss ja auch die Erwärmung davor eine andere Ursache gehabt haben - nicht Treibhauseffekt, sondern Sonne oder PDO oder so. Das Bild ganz oben von der RSS-Seite zeigt also, dass der Trend weiter geht und das natürlich das ist, was wir aufgrund des Treibhauseffektes erwarten. Aber wenn es nur noch um "Rechthaberei" geht, spielt es keine Rolle mehr. Man streitet nur darum, dass da aber mal eine Pause war. Also aufgrund zweiseitigen Rosinenpickens.
Nun kann man in verschiedener Weise dieses zweiseitige Rosinenpicken entlarven. Am einfachsten, indem man so ein Schwindeldiagramm im Kontext aller Daten zeigt:

Man sieht gleich: das ist vom Dezember 2019. Es ist langweilig, so ein Bild mit weiteren Daten neu zu erstellen, weil das Prinzip ja schon klar ist.
Ich kann aber natürlich auch die RSS-Daten herunterladen und selbst im Diagramm darstellen. Man kann also das Bild mit dem ganz oben vergleichen - bei mir ist jetzt nur die Linie dicker:

Ich kann auch eines der "Pausenbilder" von oben neu erstellen:

Ich habe auch gleich den Trend eingezeichnet - 0,13 Grad/Jahrzehnt. Aber Moment mal - wieso ein Trend? Na, die schönen Pausenbilder sind alle noch die RSS TLT 3.3-Version. Doch inzwischen sind die Verfahren verbessert worden, und wir sind bei RSS TLT Version 4.0. Wir erinnern uns: die Kalibrierungsunterschiede zwischen den Mikrowellensensoren der verschiedenen Satelliten. Hier und in anderen Details hat man Verbesserungen durchgeführt. Es hat sich nicht viel geändert - man kann mein aktuelles Bild mit dem alten "Pausenbild" vergleichen - da sind alle Zacken drin, sie sind nur minimal verschoben. Aber angesichts dieses kurzen herausgepickten Zeitraums wirkt sich das erheblich auf den Trend aus. Also ganz klar, die aktuellen Daten zeigen einfach keine Pause mehr. Die Bildchen von oben mit den angeblichen "Pausen" sind nicht nur zweiseitig rosinengepickt, sondern dazu noch veraltet. Und damit falsch.
Aber es geht noch besser: alle Bildchen zusammen behaupten, da wäre seit August 1996 eine Pause gewesen und Januar 2016 hat man das zum letzten Mal behauptet. Schauen wir uns doch mal den kompletten Zeitraum an, in dem angeblich für jeden Monat behaupten kann, dass der zu einer "Pause" gehört.

Da kommen noch 10 Monate dazu - von August 1996 bis Januar 2016 war dieses Pausentheater. Und der Trend steigt gleich noch einmal auf 0,15 Grad/Jahrzehnt. Die angeblichen Pausen waren nicht rosinengepickt, und zwar zweiseitig, sondern auch noch durch inzwischen veraltete Daten verursacht. Mit den aktuellen Daten findet man da keine "Pausen" mehr.
Und jetzt zum Schluß die angebliche Pause eingebettet in alle Daten:

Offensichtlich unterscheidet sich der Trend der angeblichen "Pause" nicht wirklich von dem aller Daten. Man sieht nur den Effekt eines Herauspickens, mit dem man die Unsicherheit vergrößert.
Sicherlich ein Augenöffner, mal mit allen Bildern im Zusammenhang zu sehen, mit welchen angeblichen "Pausen" Leugner inzwischen argumentieren.
Antwort auf Beitrag Nr.: 74.672.296 von lyta am 22.10.23 10:07:06
Stimmt absolut Lyta, auch mein Favorit 👍
Für mich ist For4zim, die talentierteste und unangefochtene, intelligenteste No. 1 bei w.o. 👏 👍
Ich bin auch sehr ernsthaft der Meinung, dass For4zim, entweder in den Journalismus oder Politik unbedingt reingehen sollte.
Besser gesagt bei seinem unfassbaren Schreibtalent, Gabe und Kompetenz zu 100%!!!! unbedingt dort reingehört!!
Da dieses tagtägliche Abnutzen mit so vielen Klimaleugner-, AfD- oder Putin Trollen, fast schon nicht mehr anzusehen ist, wieviel Dummheit aus ihren Beiträgen rausquillt.
Und das hält mit Sicherheit den For4zim vor viel, viel größeren gesellschaftlichen Aufgaben ab, zu der er meiner Meinung nach auf jeden Fall bestimmt ist.
Und jemand wie For4zim, ist bei seiner Mega Intelligenz!!, seinen unfassbaren Schreibtalenten und Cleverness, deshalb für viel höhere Aufgaben berufen, als sich jeden Tag mit so vielen unverbesserlichen Trollen in den Foren plagend rumzuschlagen.
Zitat von lyta: 👍 zu den👌 favoriten ...👏
Stimmt absolut Lyta, auch mein Favorit 👍
Für mich ist For4zim, die talentierteste und unangefochtene, intelligenteste No. 1 bei w.o. 👏 👍
Ich bin auch sehr ernsthaft der Meinung, dass For4zim, entweder in den Journalismus oder Politik unbedingt reingehen sollte.
Besser gesagt bei seinem unfassbaren Schreibtalent, Gabe und Kompetenz zu 100%!!!! unbedingt dort reingehört!!
Da dieses tagtägliche Abnutzen mit so vielen Klimaleugner-, AfD- oder Putin Trollen, fast schon nicht mehr anzusehen ist, wieviel Dummheit aus ihren Beiträgen rausquillt.
Und das hält mit Sicherheit den For4zim vor viel, viel größeren gesellschaftlichen Aufgaben ab, zu der er meiner Meinung nach auf jeden Fall bestimmt ist.
Und jemand wie For4zim, ist bei seiner Mega Intelligenz!!, seinen unfassbaren Schreibtalenten und Cleverness, deshalb für viel höhere Aufgaben berufen, als sich jeden Tag mit so vielen unverbesserlichen Trollen in den Foren plagend rumzuschlagen.
Das hat er nicht gesagt
Der Aufhänger des Threads ist der Versuch von Klimawandelleugnern, einem Wissenschaftler etwas unterzuschieben, was er nicht gesagt hatte. Wie ich im früheren Thread geschrieben hatte, steckte dahinter Methode: man bringt einen renommierten Wissenschaftler dazu, über einen Zeitabschnitt zu sagen, hier gäbe es rechnerisch keinen signifikanten Trend. Dann leitet man wahrheitswidrig das in einen Nachweis um, dass es gar keinen Trend gäbe. Das ist so, als wollte man beweisen, dass in einer Stadt keine Menschen leben, weil man sich gerade eine Straße ausgesucht hatte, durch die zufällig gerade niemand geht. Wenn man für jede Straße diesen Zeitpunkt abpasst, in dem sie gerade zufällig leer ist, kann man sich eine menschenleere Stadt einbilden. Aber natürlich ist die Vorstellung absurd. Das gleiche gilt für einen Trend - nur weil man zu wenig Daten genommen hat, um ihn rechnerisch nachzuweisen, heißt das nicht, dass es keinen Trend gibt - man braucht nur mehr Daten, um ihn zu finden. Und indem man lauter zu kurze Zeitabschnitte aneinanderreiht, kann man sich einbilden, da sei dann kein Trend mehr - aber natürlich ist das falsch. Mit mehr Klimadaten verjährt so ein Schwindel.Man ist aber noch einen Schritt weiter gegangen. Diese infame Vorgehensweise hat hier der britische Journalist David Rose (der des Öfteren Leugnerpositionen verbreitet) gewählt: https://www.dailymail.co.uk/sciencetech/article-2217286/Glob…
Betrachtet man den Artikel näher, fällt einem auf, dass Rose hier eigentlich parteipolitisch für einen extremen Flügel der britischen Konservativen argumentiert. Aber dazu braucht er eine Verfälschung des wissenschaftlichen Sachstandes.
Die globale Erwärmung hätte vor 16 Jahren gestoppt (nämlich seit Januar 1997), behauptet die Schlagzeile - eine klare Lüge, weil genau das ja nie passiert ist. Dies sei so lang wie die Periode zuvor mit einer globalen Erwärmung von 1980 bs 1996. Das ist nun ein Taschenspielertrick - die globale Erwärmung läuft seit ca. 1970. Natürlich weiß man das nicht auf das Jahr genau, weil ja von Jahr zu Jahr die mittlere Temepratur schwankt - alle Jahre zwischen ca. 1968 bis 1978 könnte man als Anfangsjahr des Trends nehmen. 1980 ist aber schon deutlich innerhalb des laufenden Trends, und wurde von Rose vor allem gewählt, weil es gut zur Erzählung passte - die trendlose Zeit sei "inzwischen" genauso lang wie die Zeit mit Trend, im Grunde wäre also die globale Erwärmung nur eine bedeutungslose Episode der Vergangenheit. Hätte man 1970 - 1996 als Periode mit globaler Erwärmung betrachtet, hätte man diese Erzählung nicht so führen können. Es kommt aber noch dazu, dass es keinen Grund dafür gibt, 1997 bis 2012 als separate Episode aufzufassen - die globale Erwärmung dauert ja in Wahrheit seit 1970 bis dato an.
Für das Täuschungsmanöber musste man sich sehr spezielle Daten herauspicken - 1995, wie damals bei mInetrview von Jones mit der BBC konnte man bereits nciht mehr nehmen - ab da gab es nämlich bereits einen signifikanten Trend. Jetzt war der angeblich trendlose Zeitraum Januar 1997 bis Augist 2012 - auf Monate genau musste man jetzt die Daten Rosinenpicken. Geht man von 1997 bis 2010 oder 2011, hat man einen erkennbaren Trend - nimmt man 8 Monate aus 2012 dazu, verschwindet der Trend, nimmt man weitere Monate hinzu, sähe man wieder einen Trend. Wie ich bereits gezeigt hatte: wenn man Trends über 15 Jahre betrachtet, kann man selbst bei den heutigen genaueren Klimadaten sehen, dass der berechnete Trend und seine mögliche Signifikanz beträchtlich je nach Startjahr schwanken. Und damals waren zusätzlich die Klimadaten mit dem HadCrut4-Datensatz noch ungenauer als mit dem heutigen HadCrut5-Datensatz und zeigten einen schwächeren Trend.
Später im Artikel wird es noch theatralischer: seit 1880 sei die Welt um ca. 0,75 Grad wärmer geworden. Und zwar bis 1996. Und seitdem um 0 Grad. Also sei die gesamte Erwärmung immer noch 0,75 Grad. Rose legt aber keine Berechnung von 1880 bis 2012 vor - die eine stärkere Erwärmung als die 0,75 Grad ergeben hätte. Rückblickend wissen wir - bis 1996 wurde es ca. 0,75 Grad wärmer, bis 2012 aber ca. 1 Grad, wenn man sich auf den bestehenden berechneten Trend bezieht.
Der Journalist David Rose läßt an dieser Stelle Wissenschaftler zu Wort kommen, darunter Prof. Jones, und sie darauf hinweisen, dass so ein Plateau in 15 oder 16 Jahren an Daten nichtssagend sei - das sei zu kurz, um daraus Schlußfolgerungen zu ziehen. "Yet he insisted that 15 or 16 years is not a significant period" - "Doch bestand er darauf, dass 15 oder 16 Jahre keine signifikante Periode sei." Hier im Thread habe ich ja mit den entsprechenden Rechnungen auf die Problematik zu kurzer Zeitreihen hingewiesen. Zunächst neutralisiert Rose die Fachmeinung mit einer Leugnerin Prof. Curry, die als seriöse Expertin präsentiert wird. Sie widerspricht aber nicht wirklich dem angeführten Argument, sondern behauptet, ohne erkennbare Begründung, dass die Computermodelle bei der Vorhersage zukünftiger Erwärmung zutiefst fehlerhaft wären. Das Eine hat mit dem Anderen nichts zu tun. Angenommen, Klimamodelle wären falsch - was hat das mit der statistischen Frage zu tun, ob die vergangenen Klimadaten einen Erwärmungstrend zeigen? Nichts. Es ist ein Beispiel für eine logische Ablenkung, eine der rhetorischen Tricks von Leugnern, um Zuhörer und Leser zu manipulieren. Und Prof. Curry sollte wissen, was sie da tut. Ich denke, es war Absicht. Inzwischen wissen wir ja, dass die globale Erwärmung weitergegangen ist und alle Unterstellungen über fehlende Trends falsch waren. Prof. Curry hat aber ihre falsche Behauptungen nie zurückgezogen. So etwas ist ein klarer Hinweis, dass ihr bei dem Thema die Fakten egal sind.
Kommen wir aber zu dem, was Prof. Jones nicht gesagt hat. Er hat nicht gesagt, dass er eine Periode von nur 15 Jahren für relevant hält, um etwas über den Klimatrend auszusagen. Er hat es nicht gesagt, weil er darauf hinweist, dass er über so eine Periode interne Variabilität für wichtig hält, zum Beispiel die Verteilung von El Nino und La Nina-Ereignissen. Ohne einen neuen El Nino könnte daher aus seiner Sicht auch der Bereich. über den man noch keinen signifikanten Trend sieht, durchaus länger werden. Hier spielt nun Rose Jones gegen Jones aus, indem er etwas gegen ihn auffährt, was Jones nie öffentlich gesagt hatte. Er zitiert aus einer gehackten Email, bei der man den Kontext nicht kennt. In der hätte Jones 2009 angeblich geschrieben: "Bottom line: the “no upward trend” has to continue for a total of 15 years before we get worried." - "Grundaussage: der "kein steigender Trend" muss insgesamt 15 Jahre anhalten, bevor wir uns Sorgen machen." Ohne den Kontext dazu kann das alles Mögliche bedeuten. Offen ist, was er mit "kein steigender Trend" meint - bezogen auf was: auf ein bestimmtes Startjahr? Die Leugner wechseln dauernd 1995, 1997, 1998 usw. als Startjahre. Und heißt "kein steigender Trend" kein signifikanter Trend? Oder ganz ohne Trend? Und wenn man sich "Sorgen macht" - was bedeutet das? Dass man dann nicht mehr an einen steigenden Trend glaubt oder dass man vielleicht sagt - ok, wir müssen uns mehr Gedanken über interne Variabilität machen?
Im Grunde behauptet hier David Rose auf Basis einer gehackten Email ohne Kontext, die er nach eigenem Gutdünken interpretiert, dass Prof Jones lügen würde - insgeheim würde er etwas anderes meinen als er in der Öffentlichkeit sagt. Aber beide Aussagen stehen gar nicht in einem Widerspruch - in der gehackten Email hat Jones nicht explizit gesagt, dass er 15 Jahre für ausreichend hält, um signifikante Trends zu bestimmen. Ohnehin hätte er seit 2009 sich überlegen können, dass zumindest der 1998er El Nino erfordert, Schwankungen durch interne Variabilität stärker zu berücksichtigen.
Und zu Ehrenrettung von Prof. Jones: seine Aussage, dass er aber sicher sei, dass das Jahrzehnt 2010 - 2020 ungefähr 0,17 Grad wärmer werden werde als das Jahrzehnt davor, hat sich als recht korrekt erwiesen. Nach Hadcrut4 stieg die mittlere Anomalie von 0,46 auf 0,61 Grad um 0,15 Grad von Januar 2000 bis Dezember 2009 im Vergleich zu Januar 2010 bis Dezember 2019. Bei HadCrut5 ist der Unterschied 0,52 auf 0,73, also 0,21 Grad. Im Gegensatz zu Prof. Curry, die von einer nicht existierenden Pause und angeblich falsch vorhersagenden Modellen fabulierte, hatte er nach heutiger Sicht nichts zurückzunehmen.
Obwohl also Prof. Jones gerade nicht erklärt hatte, man müsste immer Trends über 15 Jahre an Klimadaten erwarten, und fehlten sie, dann müsste man alles überdenken, wird aber dies über ihn fälschlich behauptet. Es ist eine falsch Unterstellung genauso wie, dass er angeblich behauptet hätte, seit 1995 gäbe es keinen Erwärmungstrend mehr obwohl er nur für eine untergeschobene Periode erklärt hatte, dass sie für einen signifikanten Trend noch zu kurz sei. Diese bewußte Verwechslung von "Es sind noch zu wenig Daten, um den vorhandenen Trend zu sehen." mit "Da ist kein Trend, auch wenn man genug Daten hat." macht aus der manipulativen Rhetorik der Leugner letztlich bewußte Lügen, die mit weiteren Klimadaten entlarvt werden. Dass es kein Versehen der Leugner ist, zeigen vor allem zwei Tatsachen: Leugner arbeiten immer wieder mit diesem rhetorischen Trick. Und Sie melden sich nie mit einer Korrektur zurück, wenn sie durch zusätzliche Klimadaten widerlegt wurden. Und das betrifft auch angeblich seriöse Wissenschaftler wie Prof. Lindzen und Prof. Curry.
Beschleunigt sich der Temperaturanstieg?
Bevor ich mich dem Thema des Vergleichs von Modellen und Beobachtungen zuwende, ein Intermezzo zur Frage, ob denn der Trend der Temperatur seit 1970 als gleichbleibend angesehen werden darf.Rein optisch könnte man ähnlich vorgehen, wie es Leugner getan haben, um eine Pause der Erwärmung zu behaupten. Leugner haben einfach einen Teil der Daten genommen und dafür einen eigenen Trend berechnet. Der war niedriger als für die Daten davor - also Verlangsamung der Erwärmung oder keine Erwärmung. Nach unserem Kurs zum Thema Rosinenpicken wissen wir, dass es ein Problem ist, wenn man willkürlich einen Start- und gar Endpunkt auswählt, um damit die Stärke des Trends zu manipulieren. Das wird um so bedenkicher, je kürzer die herausgepickte Zeitreihe ist, weil dann der berechnete Trend auch noch statistisch nicht signifikant sein könnte. Trotzdem schauen wir uns das zuerst an. Die Bodenbeobachtungen von 1970 bis 2023 teile ich ungefähr hälftig von 1970-1996 (27 Jahre) und 1996-2023 (27 Jahre). 1996 verwende ich doppelt, das macht aber für das Ergebnis wenig aus. Mit 27 Jahren habe ich auch hinreichend lange Datenreihen, um einen statistisch signifikanten Trend zu berechnen und das Jahr 1996 ist auch nicht sonderlich ungewöhnlich, und kann die Trends auch nicht besonders beeinflussen.
Für GISS (Daten der NASA - GISTemp) sieht das so aus:
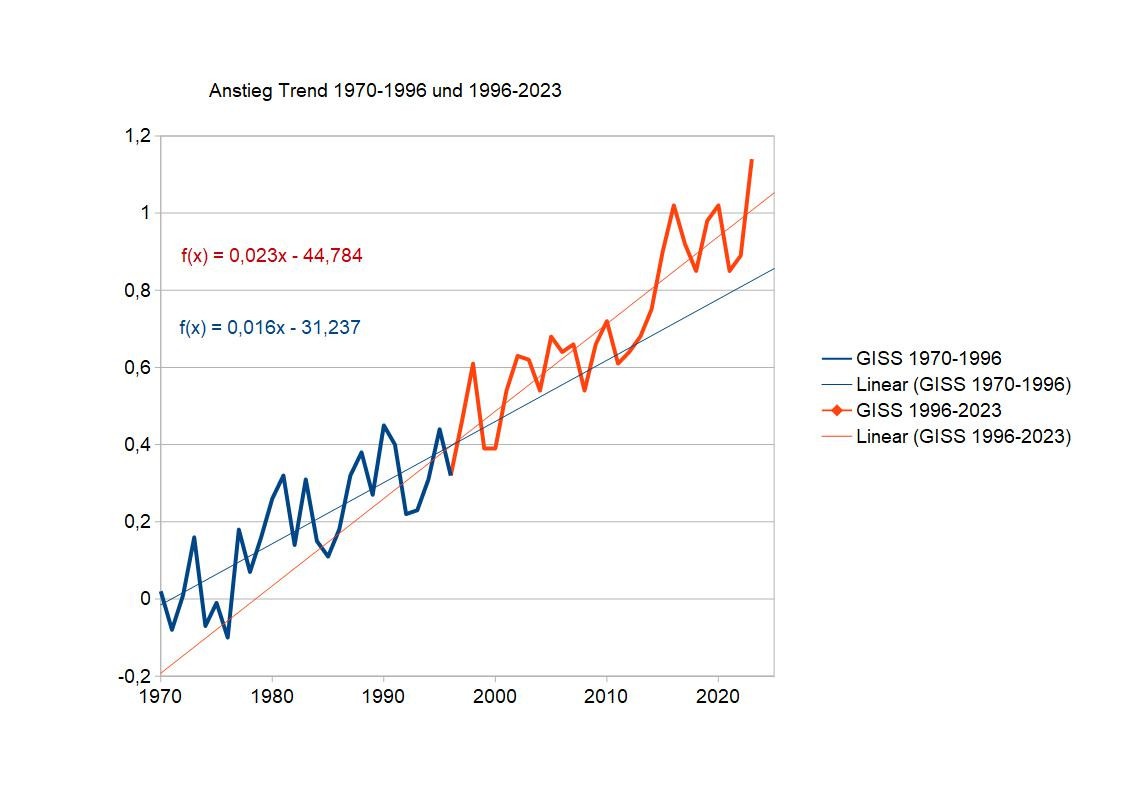
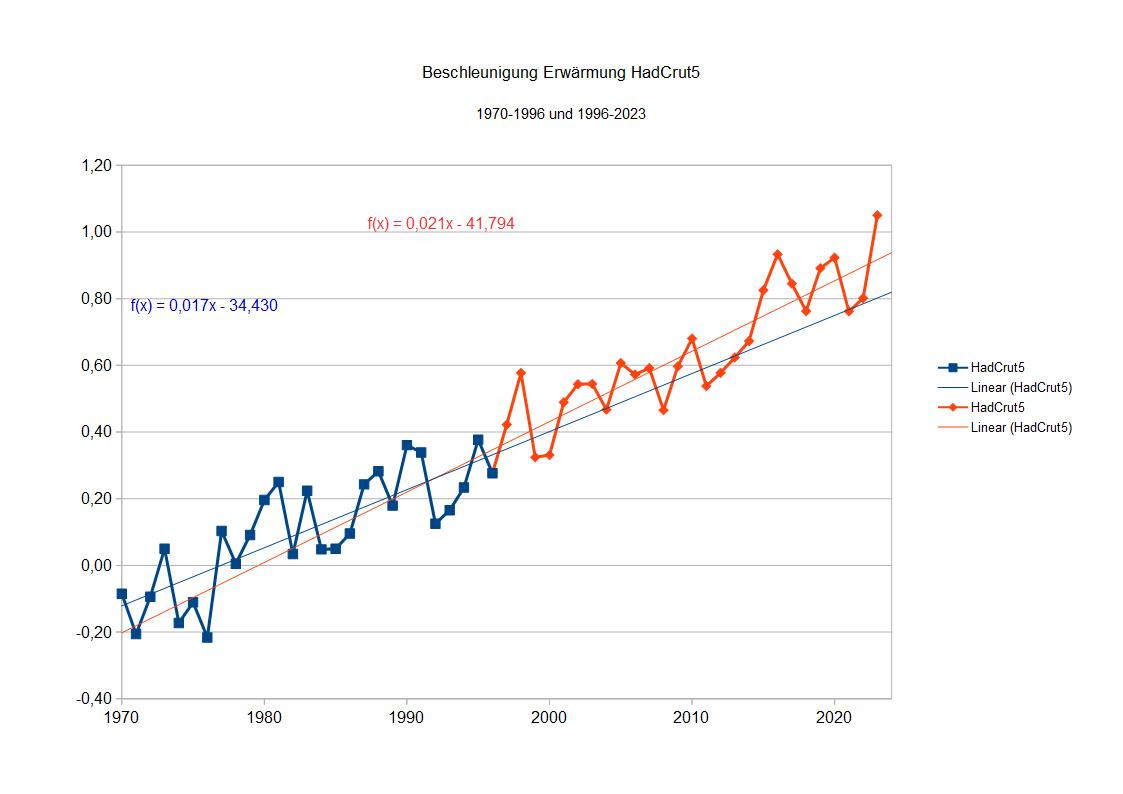
Für HadCrut5 (Daten des Hadley-Centres für Ozeanoberflächentemperaturen und der Climate Research Unit für Landdaten) sieht es so aus:
Die Satellitendatenreihe RSS ist kürzer und die Unsicherheit beim Trend größer. Ich teile im Jahr 2001 und erhalte eine 23 Jahre lange Zeitreihe 1979-2001 und eine 23 Jahre lange Zeitreihe 2001-2023:
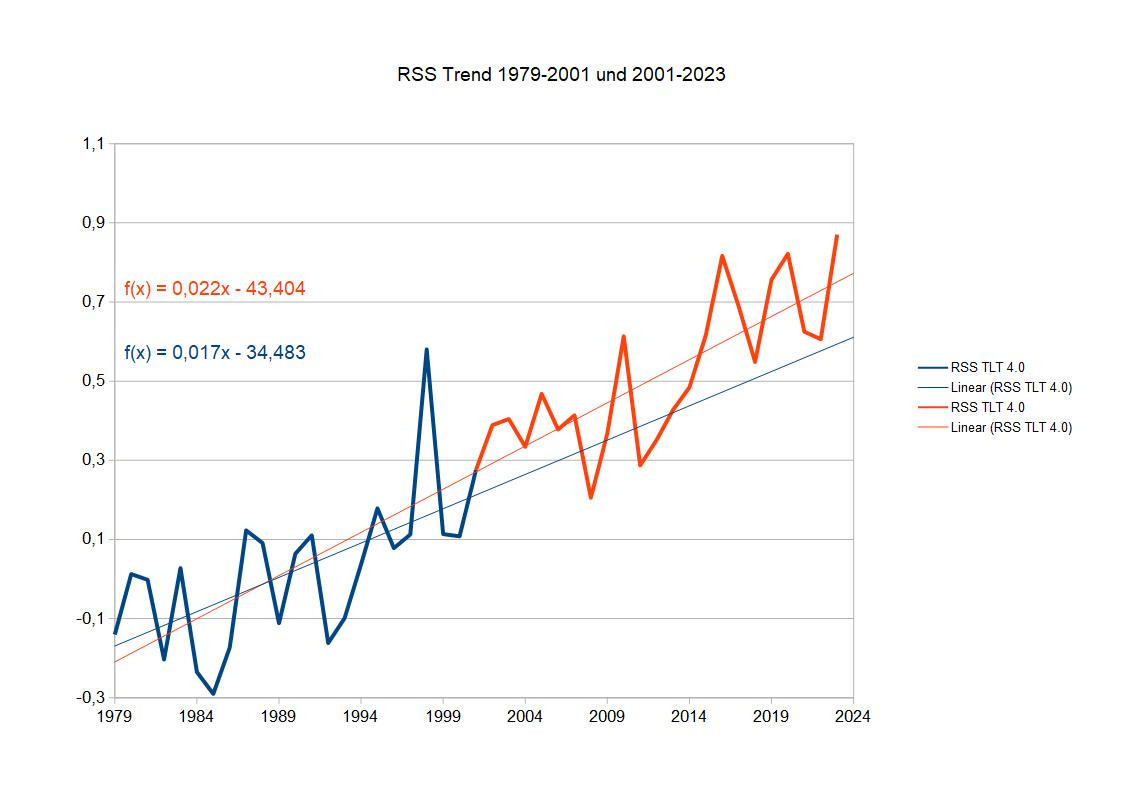
Die Trends sind also für jeweils die vordere und hintere Hälfte:
HadCrut5
0,017+/-0,003 Grad/Jahr und 0,021+/-0,002 Grad/Jahr
GISS
0,016+/-0,002 Grad/Jahr und 0,023+/-0,002 Grad/Jahr
RSS
0,017+/-0,005 Grad/Jahr und 0,022+/-0,004 Grad/Jahr
Alle Trends sind signifikant auf 99%-Niveau, allerdings der vordere Trend bei RSS nur noch knapp.
Nimmt man bei den Trends die Fehler dazu, überlappen sie sich bei HadCrut5 und bei RSS. Diese Trends unterscheiden sich vermutlich nicht signifikant. Bei GISS würde sich hingegen zumindest ein Test darauf lohnen.
Es unterscheiden sich die Trends aber sogar bei den GISS-Daten zwischen vorderer und hinterer Hälfte auf 99%-Niveau nach F-Test nicht. Bei dem lockereren 95%-Niveau ginge es so gerade - die Chance wäre 1:20, dass man die Trends als verschieden ansieht und sie es dann doch nicht sind. Das Ergebnis ist also, dass wir zwar sehen, dass der Trend bei allen Klimazeitreihen in der zweiten Hälfte höher ist, aber das ist statistisch nicht signifikant. Es wird also (noch) nicht empfohlen, die Zeitreihe zu unterteilen und aus den Daten auf eine Beschleunigung der globalen Erwärmung zu schließen. In wenigen Jahren könnte das Ergebnis anders aussehen, bei den GISS-Daten schon bald, bei den RSS-Daten wird es noch länger dauern.
Allerdings zeigen andere Daten, dass sich die globale Erwärmung doch beschleunigt. 90% der globalen Erwärmung gehen in die Ozeane. Hier sieht man deutlicher die globale Erwärmung mit geringerer zeitlicher Schwankung. Die Wärmezunahme dort zeigt eine deutliche Beschleunigung über den gesamten Zeitraum:
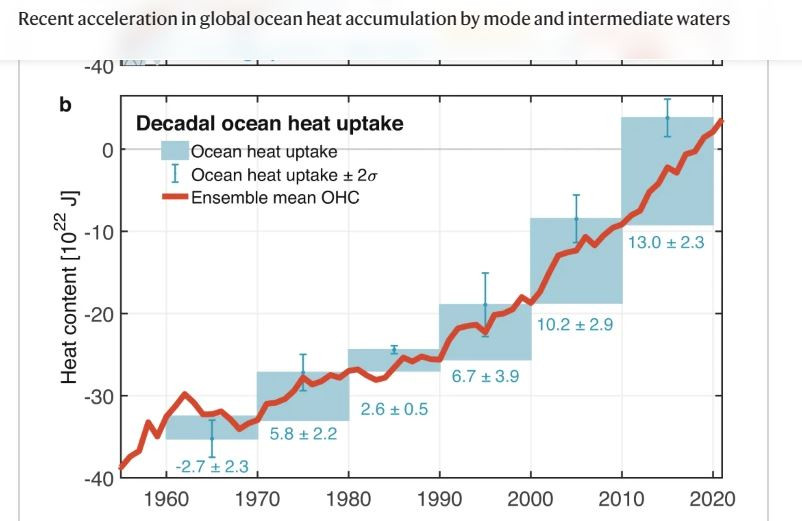
Quelle: Li, England und Groeskamp, Recent acceleration in global ocean heat accumulation by mode and intermediate waters, Nature Communications 14, Article number: 6888 (2023). https://www.nature.com/articles/s41467-023-42468-z
Am Ende zeigt sich, obwohl wir inzwischen einen recht langen Zeitraum der globalen Erwärmung haben, brauchen wir für manche Fragen immer noch mehr Daten. Nimmt man aber Informationen weiterer Datenquellen dazu, kann man trotzdemweitergehend Fragen dazu beantworten. In der Wissenschaft kann Rosinenpicken also nicht nur bedeuten, sich beliebige Teile aus Zeitreihen herauszuschneiden und den Rest zu ignorieren, es kann auch bedeuten, sich aus verfügbaren Datenquellen nur eine oder wenige (genehme) herauszusuchen und weitere relevante Querverbindungen zwischen Datenquellen auszublenden.
Rosinenpicken mit kurzen Trends
Rosinenpicken ist die deutsche Übersetzung für das englische Cherry-Picking. Die Amerikaner pflücken sich also Kirschen heraus, die Deutschen Rosinen. Klar ist, dass man etwas auswählt, was ganz anders sein kann als alles drum herum. Indem man sich etwas herausgreift und so tut, als wäre das alles, was da ist, verbirgt man die Information, die vielleicht etwas ganz anderes zeigt.Die Information, die verborgen werden soll, ist der Trend von 0,0196 +/- 0,0008 Grad/Jahr von 1970 - 2023. Man könnte den Trend besonders groß oder besonders klein erscheinen lassen, würde man sich gerade den richtigen Teil der Zeitreihe herauspicken. Die früheren Versionen von HadCrut3 udn HadCrut4 enthielten noch nicht die gesamte globale Erwärmung, weil die Datenabdeckung in der Arktis zu gering war und auch die Meeresdaten noch Fehler enthielten. Seit HadCrut5 ist der Temepraturanstieg hier ebenso groß wie bei den anderen Klimazeitreihen. Früher konnte man daher noch sogar 15 Jahre am Stück finden, die nahezu keinen Temepraturtrend zeigten. Noch kürzere Zeitreihen, die zum Beispiel ab 1998 starteten, konnten rechnerisch einen Trend bei Null haben oder sogar einen Temperaturrückgang zeigen.
Extrem kurze Trends sind besonders dreist. Aus ihnen kann man eigentlich alles zusammenstückeln, um den Eindruck zu erwecken, es gäbe gar keine globale Erwärmung.
15-Jahrestrends sind nach einem Leugnermythos bereits perfekt geeignet, etwas zu Temperaturtrends zu sagen. Angeblich würde sich Prof. Jones Sorgen machen, wenn es 15 Jahre ohne erkennbaren Temperaturtrend gibt. Zwei besonders extreme 15-Jahrestrends habe ich mal beispielhaft über den gesamten Datensatz farbig markiert. Hellblau ein besonders niedriger Trend, rot ein besonders hoher Trend.
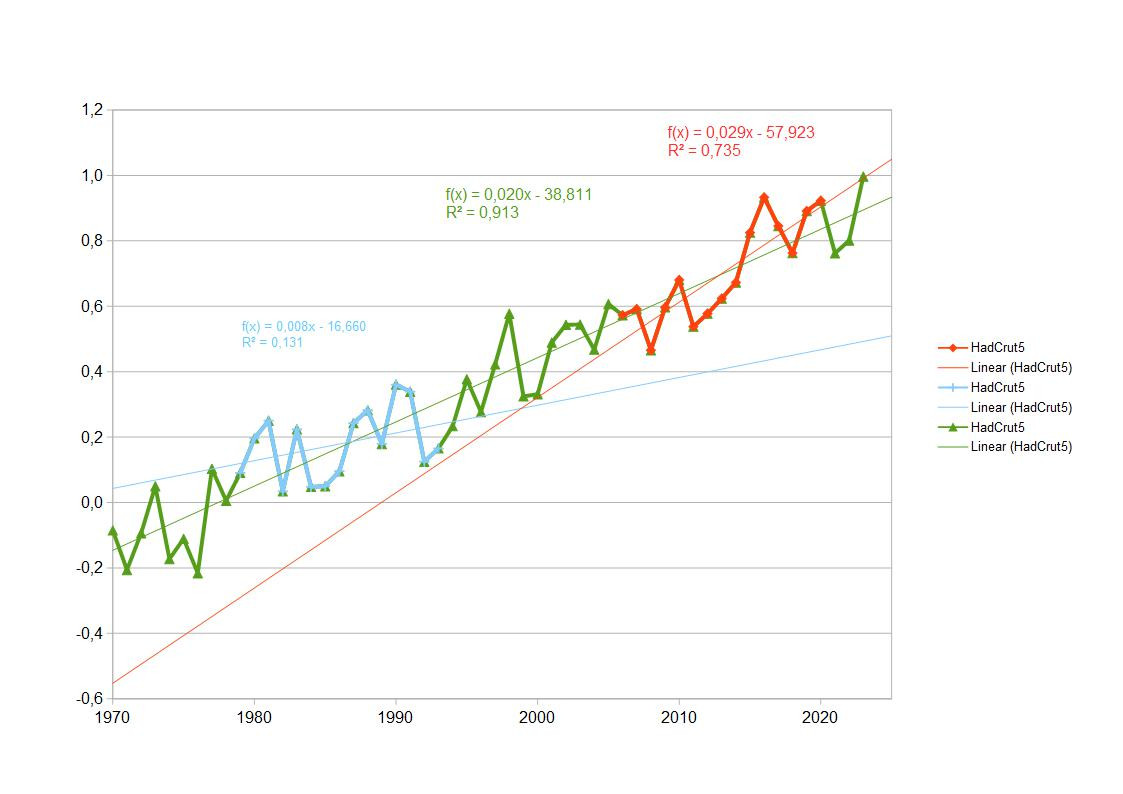
Um solche herausgepickten Ausschnitte aus der gesamten Zeitreihe geht es also jetzt.
Im folgenden Bild habe ich für alle Jahre ab 1970 den Trend für die jeweils folgenden 15 Jahre berechnet. Die Steigungen der Trends streuen um den wahren Wert von etwa 0,02 Grad/Jahr.
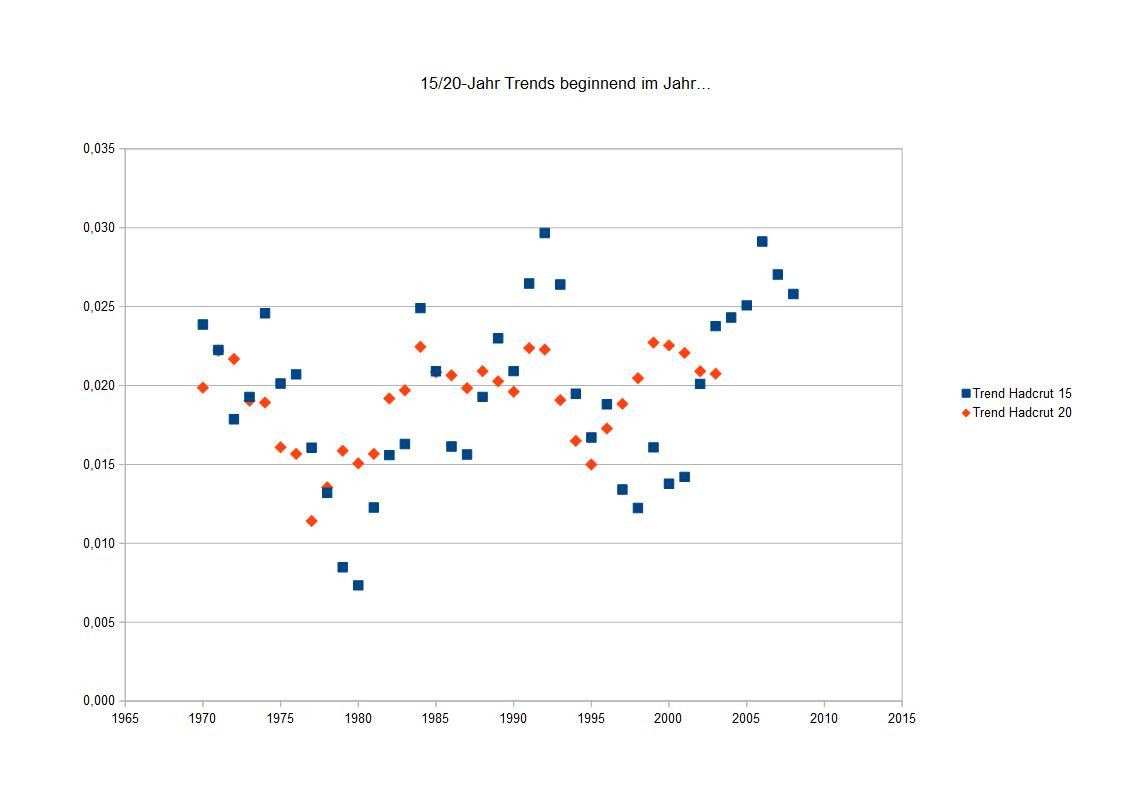
Die so berechneten Steigungen der Trends sind die blauen Punkte im Bild. Sie schwanken durchaus erheblich um den wahren Wert, den wir ja kennen - knapp unter 0,02 Grad/Jahr. Und weil sich die globale Erwärmung anscheinend etwas beschleunigt, steigen die so berechneten Trends im Laufe der Zeit etwas an.
Im gleichen Diagramm findet man auch die Trends über jeweils 20 Jahre eingezeichnet. Die schwanken bereits erheblich weniger. Das ist kein Wunder. 20-Jahr-Trends sind erheblich besser geeignet, mit vertretbarem Fehler den wahren Trend anzuzeigen. Trotzdem: kurze Trends weichen vom wahren Trend erkennbar ab. Wer behauptet, man solle sich kurze Abschnitte aus einer Klimazeitreihe anschauen, und die würden "beweisen", dass in dem Bereich die Erwärmung nachgelassen oder "pausiert" hätte, versucht mit Rosinenpicken anderen Leuten etwas vorzumachen.
Im folgenden Bild habe ich mir auch die Verteilungen der Trends herausgeben lassen. Wieder in blau für 15-Jahr-Trends und in rot für Trends über 20 Jahre. Die Verteilung für die Trends über längere Zeitreihen ist natürlich schmaler.
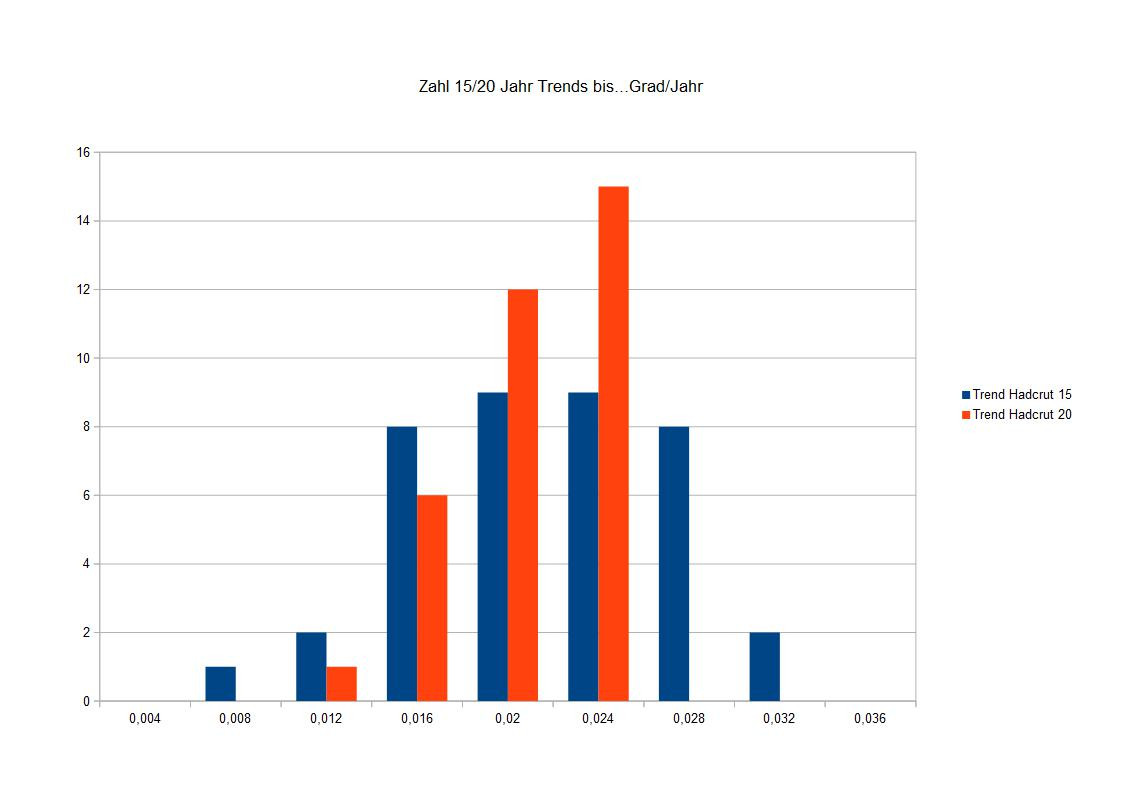
Interessant ist dabei, dass das Risiko, durch eine zu kurze Zeitreihe einen zu kleinen Trend zu erhalten, viel größer ist als einen zu hohen Trend zu berechnen. Woran könnte das nun liegen? Im Grunde liegt es am Verfahren. Die lineare Regression soll ja die Abweichungen einzelner Punkte vom Trend möglichst klein machen. Findet man die richtige Auswahl an Punkten, gelingt das gut. Der Trend ist nahe am richtigen Trend. Nimmt man aber gerade Punkte, die stark streuen, und eine schlechte Auswahl darstellen, dann ist der Trend nicht nur deutlich anders als der wahre Trend, es kann dann ein großer Teil der Streuung der Punkte gar nicht mehr durch einen Trend erklärt werden. Der Trend wird also eher falsch zu niedrig als falsch zu hoch sein. Nimmt man mehr Punkte dazu, entfallen eher die zu hohen Trends. Dass man gerade eine Stelle mit großer Streuung der Punkte erwischt, kann sich auch bei etwas längeren Zeitreihenabschnitte immer noch nachteilig auswirken.
Fazit: 15 Jahre sind sehr kurz, um einen Trend zu bestimmen. Auch 20 Jahre sind noch nicht wirklich viel. Und wenn der Trend vom wahren Trend abweicht, ist er eher zu niedrig als zu hoch. Deshalb sollte man alle Daten berücksichtigen, die man hat, jedenfalls über den Bereich, in dem ungefähr ein bestimmter Trend besteht.
Trading Spotlight
Die Kunst, gleiche Trends zu finden
Aus der Frage an Prof. Jones, ob die Trends 1860-1880, 1910-1940 und 1970-1998 verschieden wären, konnten wir den ersten Trend bereits aussscheiden - weil er nur an einem Ereignis hängt, das 1877/1878 für hohe Temperaturen sorgte, war es nur ein Scheintrend. Doch wie sieht es mit den anderen beiden Trends aus? Die sind beide echt und beide signifikant. Aber natürlich hat sich die Ausgangslage gegenüber der von Prof. Jones 2010 geändert.Die Klimadaten seitdem wurden besser. Die Abdeckungslücken in der Arktis wurden verringert, Fehler in den Daten beseitigt, Ozeandaten genauer. Die neuen HadCrut5-Daten stammen jetzt auch aus einem komplizierteren Verfahren zur Bestimmung der Gitterwerte für die Abdeckung der Erde, das man sich dort anschauen sollte: https://www.metoffice.gov.uk/hadobs/hadcrut5/
Daher waren die Trends für die beiden Zeiträume nicht mehr ca. 0,16 Grad/Dekade, sondern 0,15 Grad/Dekade bei 1910-1940 und 0,19 Grad/Dekade für 1970-1998. Man sollte denken, das wäre nun verschieden. Auch hier wäre nun die damalige Antwort der Reporterfragen an Prof. Jones von der Zeit bzw. neueren Daten überholt worden. Aber in Wahrheit ist es gar nicht so einfach, zu verstehen, ob sich zwei Steigungen unterscheiden.
Wenn man sehr einfach vorgehen will (und mathematisch nciht korrekt), betrachtet man die Steigung plus oder minus ihre statistische Unsicherheit und vergleicht sie mit der anderen Gleichung in entsprechender Weise. Die Regressionsrechnung sagt, die eine Steigung wäre 0,0147 +/- 0,0019 Grad/Jahr und die andere Steigung 0,0193 +/- 0,0024 Grad/Jahr. Addiere ich also beim kleineren Wert den Fehler, habe ich 0,0166. Ziehe ich bei der größeren Steigung ihren Fehler ab, erhalte ich 0,0169. Beide Steigungen überlappen sich also auch mit ihren Unsicherheiten nicht. Das könnte ein Hinweis sein, dass die Steigungen deutlich verschieden sind. Allerdings betrachte ich hier nur Standardabweichungen. Die wahren Werte der Steigungen liegen mit ca. 69% Wahrscheinlichkeit innerhalb ihrer Standardabweichungen. Will ich sicher sein, nehme ich das Doppelte der Unsicherheiten, und dann überlappen beide Steigungen. Will ich also eine sehr wahrscheinlich sichere Aussage machen, kann ich nicht ausschließen, dass beide Trends doch gleich sind.
Wenn ich sicher sein will, gehe ich aber nicht so hemdsärmelig an das Problem, sondern verwende einen statistischen Test. Das wäre hier der Student t-Test, den ich als zweiseitigen Test anwende mit der Nullhypothese, beide Trends seien gleich. Wie sicher kann ich mir also sein, dass beide Trends verschieden sind, um die Nullhypothese auszuschließen? Wenn ich die Differenz der beiden Steigungen durch die Wurzel der Summe der Quadrate der Unsicherheiten der Steigungen dividiere, bekomme ich einen Schätzwert für die t-Statistik. Den kann ich mit dem Grenzwert vergleichen, der sich aus einem gewählten Signifikanzniveau (zum Beispiel 5%) und der Summe der Freiheitsgrade (jeweils die Zahl der unabhängigen Werte -1) -2 ergibt. Diese Werte der t-Statistik kann man aus Tabellen ablesen. Im vorliegenden Fall ist der berechnete t-Wert 1,54 und daher deutlich kleiner als der Grenzwert für t. Ich kann die Nullhypothese also nicht ausschließen und muss annehmen, dass beide Steigungen durchaus gleich sein könnten.
Die Situation wird auch nicht besser, wenn ich der Vermutung nachgehe, dass vielleicht die Erwärmung ab 1910 nicht bloß bis 1940, sondern bis 1945 anhält. Die lineare Regression für diesen Fall liefert nämlich eine etwas höhere Korrelation der Daten und einen etwas höheren Trend - statt 0,147 nämlich 0,156 Grad/Dekade. Und damit ist der Trend dem von 1970-1998 noch ähnlicher geworden. Ich kann sie statistisch betrachtet nicht sicher unterscheiden.
Versuche ich einen noch längeren Trend zu erzeugen (bedenklich nahe am Rosinenpicken), indem ich 1905 - 1945 betrachte, bin ich bereits über das Optimum hinaus - der Trend sinkt auf 0,0142+/- 0,0012 Grad/Jahr, die Korrelation der Daten ist nun niedriger als bei den anderen Fällen. Der Unterschied zwischen diesem Trend und dem von 1970-1998 ist immer noch nicht signifikant, aber jetzt ganz knapp auf dem 5%-Niveau.
Was man also lernt: obwohl der Unterschied zwischen dem Trend 1970-1998 von 0,19 Grad/Dekade und 1910-1940 von 0,15 Grad/Dekade bzw. 1910-1945 von 0,16 Grad/Dekade erkennbar zu sein scheint - statistisch ist nicht sicher, ob sich diese Trends unterscheiden.
Allerdings haben wir etwas noch nicht überprüft. Den Trend 1970-1998 zu betrachten ist ja reine Willkür. Damals hätte man in Wahrheit 1970-2009 vergleichen müssen, denn dafür waren die Daten bereits vorhanden. Mit HadCrut5 ist hier der Trend 0,0188+/-0,0013 Grad/Jahr. Dieser Trend unterscheidet sich kaum von dem 1970-1998. Kein Wunder. Die Daten zeigen keinen Bruch des Trends - es gab nie einen logischen Grund, 1998 die Reihe abzubrechen. Statistisch liegen die Trends nun etwas weiter auseinander, sind aber immer ncoh nicht signifikant verschieden. Betrachte ich schließlich den Trend, den ich inzwischen bestimmen kann, nämlich 1970-2023, ist die Steigung mit 0,0196+/-0,0008 Grad/Jahr auf dem 5%-Niveau plötzlich verschieden zu den beiden Steigungen 1910-1940 und 1910-1945. Mit deutlich mehr Werten ist nun auch der Fehler der Steigung noch mal erheblich gesunken, und genau das macht den Vergleich der Steigungen empfindlicher. Auch hier gilt: wenn mehr Daten berücksichtigt werden, werden einstmals richtige Aussagen nun falsch.
Ist der Trend 1910-1940 bzw. 1910-1945 gleich dem von 1970-2023? Statistisch gesehen: nein.
Extremismus bei Daten
Wenn Daten extremistisch werden, geht das selten gut aus. Solche Daten nennt man Ausreißer und sie sind echte Spielverderber. Angenommen, jemand will etwas über die Größenverteilung von Menschen erfahren. Er lässt durch einige Assistenten eine größere Zahl von Menschen vermessen und sammelt die Daten. Dummerweise ist mit der beabsichtigten Zufallsstichprobe etwas nicht in Ordnung. Einer der Assistenten, die Menschen zufällig auswählen und messen sollten, hatte sich die Sache zu einfach gemacht und nur seine Kumpels aus dem Basketballverein vermessen. Als vorsichtiger Auftraggeber berechnet man bei jedem Datensatz eines Assistenten den Mittelwert. Einige Mittelwerte der Teilgruppen liegen ein bisschen über dem Mittelwert für alle Menschen und einige ein wenig darunter. Aber bei einem der Datensammler ist der Mittelwert deutlich anders – das ist der, der lauter lange Lulatsche aus der Baskeballsportlerszene kennt. Sein Datensatz ist nicht so, wie die anderen. Also ein Ausreißer.Wenn man Daten auswertet, tut man gut daran, nach Ausreißern zu suchen. Das sind nicht etwa Daten, die falsch sind, sondern nur solche, die zur Verteilung der übrigen Daten nicht passen. Je nach Art der Auswertung würden die Ausreißer die gesamte Statistik verschieben.
Das Problem ist dabei, zu bewerten, ab wann ein Datenpunkt ein Ausreißer ist. Das kann einfach sein. Ein Kriterium kann nämlich sein, bei einer Verteilung von Daten ihre Standardbreite zu bestimmen, das heißt eine Standardabweichung in jede Richtung. Wenn also die mittlere Größe zufällig auch die häufigste Größe ist und die etwas größeren oder kleineren Größen eine normale Verteilung haben, dann umfasst die Standardabweichung in beide Richtungen ungefähr 68% der Werte. Innerhalb von 2 Standardabweichungen in beide Richtungen findet man ca. 95% der Werte. Außerhalb von 3 Standardabweichungen weniger als 0,27% der Werte. Wenn ich zum Beispiel eine Gruppe mit 100 Werten habe, vermute ich, dass ich dabei keinen Wert habe, der außerhalb von 3 Standardabweichungen liegt. Es ist aber nicht unmöglich.
Ein Ausreißertest kann mir sagen, ob ein Wert so weit außerhalb einer Verteilung liegt, dass er ein Ausreißer ist. Dabei muss ich festlegen, ab welchem Niveau ich die Abweichung für signifikant halte, wie groß die Standardabweichung ist und wie viele Werte ich betrachte und mich darauf festlegen, ob ich diesen Test für eine Normalverteilung oder eine andere Form der Verteilung der Daten mache. Es gibt viele solche Tests. Sie alle tragen die Namen irgendwelcher Statistiker wie Grubbs-Ausreißertest oder Nalimov-Ausreißertest, und jeder Statistiker schwört, dass sein Test der beste ist für die von ihm festgelegten Bedingungen.
Wir erinnern uns jetzt, dass ein BBC-Reporter Prof. Jones von der Climate Research Unit 2010 gefragt hatte, ob die Trends 1860-1880 und von 1910-1940 und von 1970-1998 sich unterscheiden. Ich hatte darauf hingewiesen, dass die Frage ein Problem enthält. 1860-1880 hängt der Trend fast nur an den Temperaturanomalien von 1877 und 1878, die ungewöhnlich hoch liegen. Ist ungewöhnlich hoch jetzt aber nur mein Bauchgefühl?
Schauen wir uns an, wie stark sich in jedem Jahr die Temperatur von der im Vorjahr unterscheidet. Ich betrachte das aber für die HadCrut5-Daten. Für alle Daten berechne ich den die Temperatur minus der vom Vorjahr. Dann zähle ich aus, wie viele Differenzen davon kleiner als -0,25 Grad, kleiner als -0,2 Grad usw. bis größer als 0,35, aber kleiner als 0,4 Grad sind.
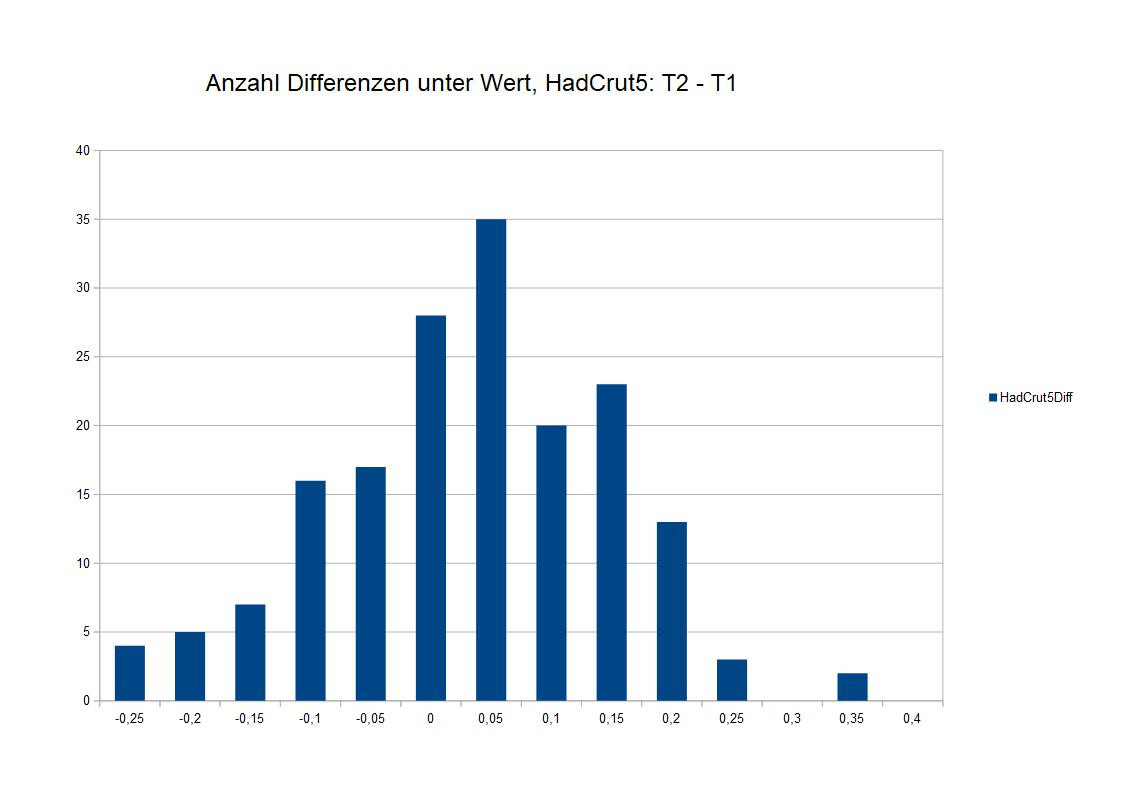
Das Ergebnis sieht man im Bild. Es sieht ein wenig wie eine Normalverteilung aus, aber sie ist etwas schmaler. Extreme Werte, die um mehr als 0,3 Grad vom häufigsten Wert abweichen, kommen fast gar nicht vor. Der Mittelwert der Verteilung ist natürlich auch nicht 0. Es sollten gleich viel Werte im Kasten 0 (-0,05 bis 0) und 0,05 (0 bis 0,05) sein, wären die Differenzen nur zufällig verteilt. Ca. 80 der Daten tragen aber das Signal einer globalen Erwärmung. Die sorgt dafür, dass das Mittel um ca. 0,01 Grad nach oben verschoben ist und dadurch der 0 – 0,05-Kasten stärker besiedelt ist als der -0,05-0 Kasten. Auch weitere positive Kästen sind stärker besiedelt als vergleichbare Kästen im negativen Bereich. Und zwei Werte haben sich etwas von dem Rest abgesetzt. Sie haben eine Differenz von mehr als 0,3 Grad (bis 0,35 Grad).
Ich könnte jetzt ein bisschen Statistikrechnereien spielen und einen Ausreißertest einsetzen. Aber aus Erfahrung kann ich gleich sagen – nein, in diesem Fall habe ich keine statistischen Ausreißer. Die 2 Werte mit 0,3 bis 0,035 Grad Differenz sind lediglich extrem, aber nicht extremistisch. Aber einer davon ist die Differenz der Temperatur von 1877 zu 1876. Und das macht 1877 und das noch etwas wärmere 1878 zu Kandidaten für ungewöhnlich hohe Temperaturen, selbst wenn sie keine Ausreißer im statistischen Sinne sind. Aber ein Klimatrend kann diese Werte nicht so hoch geschoben haben, sondern eher ein kurzzeitiger Sondereffekt.
Was ich jetzt nicht zeige – ich kann mir die gleiche Verteilung auch nur für die Werte 1850 bis 1880 anschauen. Das sind mit 29 ein bisschen wenig Werte, um noch eine Verteilung zu bestimmen, aber immerhin ist diese Verteilung schmaler, denn größere Differenzen sind hier noch weniger wahrscheinlich. Und zwei Werte stechen nun klar heraus: der Anstieg 1876-1877 und der Abfall 1878 bis 1879.
Mit diesen Ausreißern (nicht im statistischen Sinne, aber doch relativ zu üblichen Werten der Verteilung) ist es eigentlich sinnlos, für 1860-1880 einen Trend zu berechnen und so zu tun, als hätte das etwas mit einer Klimaänderung zu tun. Mir ist unbegreiflich, warum Prof. Jones nicht darauf hingewiesen hatte.
Man kann auch sagen, was eigentlich die Ursache für die beiden Ausreißer war. Die Ursache findet man in einer Tabelle für den ENSO-Index. Ich greife ihn aus diesem Datensatz Niño 3.4 SST Index heraus. https://psl.noaa.gov/gcos_wgsp/Timeseries/Data/nino34.long.a…
Es gibt nur 4 El Nino-Ereignisse nach diesem Index, die stärker sind als ein Indexwert von 2,4. Das sind 1983, 1998, 2016 und...1878. Jahre, die jeweils einen Temperaturrekord gegenüber allen Jahren davor zeigen. Und damit ist klar: 1877/1878 waren ungewöhnlich warm, weil sich zu der Zeit El Nino-Bedingungen aufbauten. Warum es bereits 1877 eine hohe Temperatur gab, ist nicht ganz so klar, aber der Indexwert ist 1876 noch klar negativ und wechselt für 1877 in den positiven Bereich, was heißen könnte, dass hier bereits der Wechsel von La Nina zu El Nino erfolgte. Das ist ein starker Hinweis, dass da 1860 bis 1880 kein echter Klimatrend vorliegt, sondern nur ein Ausreißer-Effekt durch einen Super-El Nino. Selbst wenn der Trend 1860-1880 nicht bloß halb so groß wäre als 1970 bis 1998, er ist nicht vergleichbar und kein Klimatrend.
Jesus auf dem Toast
Ich verwende immer wieder den Begriff „Trend“, oft im Zusammenhang mit „signifikant“. Wenn man sich jahrelang mit Klimadaten beschäftigt oder sowieso einen naturwissenschaftlichen Hintergrund hat, weiß man, was hinter dem Begriff steckt. Aber manche wissen es auch nicht oder nur sehr ungefähr und manche wissen zu viel darüber, aber leider über nichts Anderes. Um zu erklären, was ein Trend ist, sollten wir uns Jesus zuwenden.Vielleicht ist es nur ein lustiger Gag bei der Cartoon-Serie The Simpsons, vielleicht ist es Ausdruck religiöser Hysterie in den USA, aber das Erscheinen von Jesus auf einer Scheibe Toast scheint in den USA ernsthafter Diskussionsstoff zu sein. Hierzulande hört man weniger davon. Den meisten Menschen ist klar, dass ein zufälliges Bräunungsmuster auf der Toastscheibe auch nur genau das ist. Trotzdem „sehen“ wir Jesus auf dem Toast, wenn wir wollen.
Wir Menschen sind nämlich unheimlich gut darin, irgendwo Muster zu sehen, auch da, wo keine sind. Wir erkennen also in der zufälligen Bewegung von Blättern und der Verteilung der Schatten, dass dahinter ein Löwe lauert. Diejenigen von uns, die skeptischer sind und der Sache auf den Grund gehen, haben dann ihren Erfolg, wenn sich der Löwe in Wahrheit als ein Wildschwein herausstellt oder eben nur zufällig verteilte Blätter. Aber wenn es doch ein Löwe ist? Die Mustererkenner und Gläubigen können hinterher davon erzählen. Die Skeptiker fehlen in der Fortpflanzungslinie. Evolution macht uns also zu Mustererkennern.
Wenn man gut Jesus erkennen kann, kann man auch gut erkennen, dass die Daten im zeitlichen Verlauf nicht irgendwie zufällig herumhampeln, sondern sich entwickeln – auf oder ab. Sie haben einen Trend. Glauben wir. Aber ist da wirklich ein Trend? Weil wir so gute Mustererkenner sind, reicht uns ein markanter Punkt aus, um in der ganzen Zeitreihe eine höhere Ordnung zu erkennen. Ein hoher Punkt am Anfang, zwei niedrige Punkte am Ende, und uns ist völlig egal, dass zwischendurch die Punkte nur zufällig schwanken. Wir sind überzeugt davon, dass hier ist ein fallender Trend ist. Aber, der Computer sagt „nein“. Denn ein Trend ist nur, was man auch berechnen kann.
Das Mittel der Wahl ist die lineare Regression. Für die gibt es allerdings Bedingungen:
- Es müssen relativ zur Streuung genug Daten vorhanden sein. Je stärker die Daten um die Ausgleichsgerade streuen, desto mehr Punkte sind erforderlich, um am Ende ein belastbares Resultat zu haben. Bei der klimatologischen Temperaturzeitreihe sind oft mehr als 20 Jahre an Daten erforderlich, um so gerade einen Trend zu bestimmen, sonst überlagert die zufällige Verteilung von El Nino und La Nina den Trend. 30 Jahre und mehr geben dann vernünftige Trendwerte.
- Man nimmt an, dass die Punkte zufällig um die Ausgleichsgerade streuen. Das ist aber nicht mehr der Fall, wenn die Abweichungen der Daten von der Geraden nicht unabhängig voneinander sind. Ist also ein Punkt über der Geraden und der folgende Punkt ist dann meistens auch über der Gerade, spricht man von einer Autokorrelation der Daten. Ist das der Fall, wird man den Trend mit linearer Regression zu hoch und seine Unsicherheit zu niedrig berechnen. Klimadaten haben tatsächlich eine gewisse Autokorrelation.
- Der Zusammenhang zwischen Zeit und Daten muss wirklich linear sein. Für kurze Zeitabschnitte kann man das annehmen. Über viele Jahrzehnte hinweg können sich aber die Klimaantriebe stark ändern und sogar von einer Abkühlung zu einer Erwärmung oder umgekehrt wechseln. Mit eigenen statistischen Berechnungen kann man Trendbrüche bestimmen. Auch die Trendbruchpunkte haben eine Unsicherheit von mehreren Jahren.
Um das herauszufinden, haben findige Mathematiker die lineare Regression erfunden. Sie ist das einfachste Mittel einen linearen Zusammenhang zwischen erklärender und erklärter Variable zu finden. Ich habe also im Laufe der Zeit einige Male aufgeschrieben, wie viel ich nachts ausgegeben hatte und wie viele Kölsch ich getrunken hatte. Im Idealfall kann ich also im Diagramm auf einer Seite die Zahl der Kölsch auftragen und auf der anderen Seite die gesamten Ausgaben. Herauskommen soll eine Linie, aber in Wahrheit streuen die Punkte für die beiden Variablen ziemlich herum. Jeder Punkt zieht die Linie zu sich heran. Je weiter ein Punkt von der Linie weg ist, desto stärker zieht er. Ich suche das Optimum, in der ich alle Abstände der Punkte von der Linie am kleinsten halte. Damit das Verfahren empfindlich ist, nehme ich noch nicht mal die Abstände der Punkte von der Linie, sondern ihre Quadrate. Damit bekommen Punkte, die sich stark von den anderen Punkten unterscheiden, auch ein ziemlich hohes Gewicht. Die lineare Regression oder Ausgleichsgerade ist also sehr empfindlich für Ausreißer. Die sollte man deshalb besser entfernen, bevor man mit Rechnen anfängt. Daher kommt bei der linearen Regression der Temperaturdaten für 1860-1880 Unsinn heraus - die Daten für 1877/1878 sollte man eigentlich herausnehmen, und dann ist da auch kein signifikanter Trend mehr.
Will man einen Trend bestimmen, ist die erklärende Variable die Zeit. Im einfachsten Fall hat man genau zwei Punkte. Da geht immer eine Gerade hindurch. Die kann aber furchtbar falsch sein. Hat man nur wenige Punkte, kann es hingegen leicht passieren, dass sich die Punkte gar nicht für einen Trend entscheiden können. Sie streuen zu stark. Streuen die Punkt stark in alle Richtungen, braucht man sehr viele von ihnen, bevor sie einen Trend ergeben. Ist die Streuung der Punkte hingegen sehr klein, kann man schon mit wenigen Punkten den Trend berechnen. Damit wären wir beim ersten Problem der Trendberechnungen: gibt es im Verhältnis zur Streuung genug Punkte? Ist die Zeitreihe lang genug? Ist der berechnete Trend auch signifikant? Man kann das Verhältnis von Streuung zu Trend benutzen, um zu entscheiden, ob ein signifikanter Trend vorliegt. Man vergleicht das mit Tabellenwerten – im einfachsten Fall nennt man das t-Test, für Regressionen mit mehreren erklärenden Variablen gibt es auch einen F-Test. Was man jeweils genau berechnet, soll man nachschlagen, für diesen Beitrag wird das zu detailliert. Lineare Regression wie auch F-Test kann man sich leicht in einer Tabellenkalkulationsroutine wie Excel ausrechnen lassen oder programmieren. Einen Hinweis geben auch die Unsicherheiten der Trendvariablen und die Korrelation der Variablen. Sind die Unsicherheiten der Geradensteigung ungefähr so groß wie die Geradensteigung selbst oder liegt die Korrelation unter 0,5, dann muss man nicht viel auf den berechneten Trend geben.
Meine Philosophie dazu ist, dass man darauf achten sollte, dass die berechneten Ergebnisse eindeutig sind. Wenn es empfindlich darauf ankommt, welche statistische Methode man wählt oder die Ergebnisse gerade so eben signifikant sind oder die Fehler recht groß, dann führt das nur zu sinnlosen langen Diskussionen mit Experten (von denen jeder präferierte Methoden hat) und Laien (die verwickelte Herleitungen nicht verstehen und nicht folgen können, wenn man irgendeine Spezialmethode braucht, um noch eine Aussage aus den knappen Daten herauszukitzeln).
Aus diesem Grunde verwende ich hier durchweg Standardmethoden und achte darauf, dass die Ergebnisse eindeutig sind, das Signifikanzniveau hoch ist (99%) und die Fehler klein sind gegenüber den ermittelten Ergebnissen. In diesen Fällen geben alle Methoden das gleiche Ergebnisse und kann Autokorrelation der Klimadaten vernachlässigt werden.
Außerdem ist das reine statistische oder mathematische Ergebnis wertlos ohne den naturwissenschaftlichen Kontext. Selbst wenn ich weiß, dass es einen Trend gibt, weiß ich ohne den Kontext nicht, warum. Aus der Tatsache, dass die Temperatur steigt oder wie stark sie es tut, ergibt sich keineswegs, dass es von Menschen verursacht wurde. Daher können sich Statistiker mit völlig korrekten Ergebnissen, die sie aber ohne physikalisches Verständnis des betrachteten Systems interpretieren, furchtbar verhauen. Was im Zusammenhang mit dem Leugnen des Sachstands zum Klimawandel beabsichtigt sein kann.
Was war denn nun eigentlich der Schwindel?
@Lyta: 
Nachdem ich erklärt habe, worum es im Thread geht und im zweiten Beitrag erst einmal die Daten vorgestellt habe, um die es sich dreht, will ich jetzt auf die Motivation eingehen. Was war denn eigentlich das, was ich als Schwindel bezeichne? Im ersten "Schwindel-Thread" hatte ich ja auf die Fragen hingewiesen, die ein BBC-Journalist namens Harrabin Prof. Phil Jones vom Hadley Centre gestellt hatte. http://news.bbc.co.uk/2/hi/science/nature/8511670.stm
Die Fragen kamen im Nachgang zu einer der schlimmsten Desinformationskampagnen gegen die Klimaforschung überhaupt. Leugner bezeichneten den 4. IPCC-Bericht als Schwindel, die Temperaturmessungen als Schwindel, die Temperaturrekonstruktionen nach Mann, Bradley und Hughes als Schwindel. Das ging ab 2006 in die intensivere Kampagne. Wissenschaftler bekamen Hasmails und Morddrohungen, es gab Forderungen, die Forscher ins Gefängnis zu bringen, ihre Familien wurden bedroht. In dieser Kampagne wurden auch die Emails der Climate Research Unit der East Anglia gehackt. Spuren führten zu einem Server in der Ukraine und vermutlich hatte eine russische Hackergruppe den Leak durchgeführt. Es wurde jedoch offiziell nie ermittelt, wer hinter dem Leak stand. Die Emails wurden an Leugnergruppen weitergegeben und einzelne Auszüge so bearbeitet, um Forscher als angebliche Betrüger dastehen zu lassen. Prof. Jones stand im Zentrum einer Hasskampagne und hätte aus Verzweiflung fast Selbstmord begangen. Untersuchungen wurden eingeleitet, doch alle beschuldigten Wissenschaftler wurden entlastet. Niemand hatte betrogen, alle Anschuldigungen waren falsch.
Die Medien jedoch nahmen die Desinformationskampagne auf, stellten die Klimaforschung unter Verdacht, Magazine wie der Spiegel und sogar die altehrwürdige BBC sprangen auf dem Zug der Leugner auf. 2021 wurde der Skandal über die Kampagne der Leugner mit den gestohlenen Emails als The Trick verfilmt: https://www.theguardian.com/environment/2021/oct/10/this-is-…
Im Nachgang zu dieser Kampagne gegen Jones fand das Interview mit dem BBC-Reporter Harrabin statt, der dem Professor offenbar nicht wohlgesonnen war. Die Fragen waren mit der Leugnerszene abgesprochen. Lindzen, der Leugnerblogger Watts und ein tschechischer Leugner-Blogger namens Motl hatten in der Diskussion untereinander die Fragen erstellt und dem BBC-Reporter gegeben. Über den Hintergrund dieser kleinen Leugnerverschwörung hatte ich bereits im ersten Schwindel-Thread erzählt, Details stehen hier: https://deepclimate.org/2010/03/02/round-and-round-we-go-wit…
Eine der Fragen war, ob der Temperaturtrend seit 1995 (damals bis 2009) signifikant wäre. Das war er nicht - 15 Jahre sind zu kurz, um einen signifikanten Temperaturtrend sicher festzustellen). Aus der korrekten Antwort Jones, der Trend sei gerade noch nicht signifikant, wurde fälschlich das Fehlen einer globalen Erwärmung seit 1995 gefolgert. Das war natürlich falsch. Schon ein Jahr später gab es daher die Meldung der BBC: der Temperaturanstieg seit 1995 ist nun statistisch signifikant. https://www.bbc.co.uk/news/science-environment-13719510 In einer gerechten Welt hätte das die Leugnerkampagne erledigen müssen.
Aber die Realität ist anders: kein Mensch hat die Richtigstellung mitbekommen. Die falsche, aber aufregende Behauptung, dass Prof. Jones selbst zugegeben hätte, seit 1995 gäbe es keine Erwärmung, ging viral. Die langweilige Korrektur, wie so oft, ging hingegen unter. Und auch die Leugner gaben natürlich nie zu, dass ihre Schlagzeile Jones Antwort falsch wiedergab und nach einem Jahr auch sachlich falsch war. Im ersten Schwindelthread hatte ich ab 2014 Jahr für Jahr vorgerechnet, dass inzwischen Trends ab 1995 und später auch ab 1998 signifikant waren, und zwar bei den wichtigsten Bodenmessdaten und auch bei den Satellitendaten. Wer die Rechnungen sehen will, sie sind im anderen Thread, leider sehr verteilt in einem Meer von wüsten Anfeindungen, Ablenkungen udn Falschbehauptungen von Leugnern.
In diesem Thread will ich aber einen anderen Punkt betrachten. In einer anderen Frage des BBC-Reporter Harrabin an Jones wurden die Trends von 1860-1880 und 1910-1940 mit dem von 1970-1998 verglichen. Mit den damaligen Daten der HadCrut4-Reihe schienen diese Trends alle gleich zu sein. Für Leugner ein Zeichen, dass die globale Erwärmung ab 1998 nichts Besonderes sei, sondern natürliche Ereignisse seien, die mit dem Treibhauseffekt gar nichts zu tun hätten. Auch dieser Trendvergleich wurde von Leugnern gerne und oft verbreitet.
Die Wahrheit hatte ich bereits in Beitrag 2 dargestellt: die drei Trends sind sehr verschieden. Den von 1970 - 1998 hatte ich nicht eingestellt, aber er ist 0,019 Grad/Jahr und signifikant. Mit den HadCrut5-Daten sind die Trends 1860-1880, 1910-1940 und 1970-1998 also verschieden: 0,009 Grad/Jahr, 0,015 Grad/Jahr und 0,019 Grad/Jahr. Der erste Trend zudem ist nur ein Scheintrend, der an 2 Datenpunkten hängt. Die Erzählung, die Erwärmung ab 1970 sei schon vorher ähnlich passiert, daher auch als natürliches Ereignis erklärbar, stellt sich als Schwindel heraus.
👍 zu den👌 favoriten ...👏















